
Introduction
Tired of chatbots that fumble your meaning? My research breaks new ground with a world-first conversational search system that grasps your intent, even for muddled questions. This innovative approach hinges on two key advancements:
Unveiling Hidden Meaning: The system employs cutting-edge techniques to unlock the true intent behind your queries. First, a Dialogue Heterogeneous Graph Network (D-HGN) meticulously analyzes past conversations, extracting the semantic context. This allows the system to understand the connections between your current request and prior interactions. Second, a custom-designed dataset fine-tunes the AI’s ability to recognize and respond to ambiguous user queries with multiple potential meanings.
Limitless Knowledge at Your Fingertips: Imagine a chatbot with the combined knowledge of Google and Bing! This system seamlessly integrates with search engines, granting it access to a virtually limitless knowledge base. This ensures factually accurate and highly relevant responses to your questions.
Intrigued? Stay tuned for a deeper dive into this groundbreaking system that outperforms existing models by a staggering 30-50% on a collection of metrics including BLEU, ROUGE, and F1. The actual improvement in more measurable through dialogue examples.
Background
Conversational AI has made significant strides in recent years, with chatbots becoming increasingly prevalent in our daily lives. However, these systems often struggle to understand user intent, leading to frustrating and unproductive interactions.
The core challenge lies in the complexity of human language. People frequently use ambiguous phrasing, colloquialisms, and incomplete sentences, making it difficult for AI to accurately interpret their meaning. The state-of-the-art conversational AI models that use the revolutionary large language models LLM typically rely on predicting the next word in a sentence or generating responses based on pre-defined templates, limiting their ability to understand nuanced queries.
 Example 1.
Example 1.
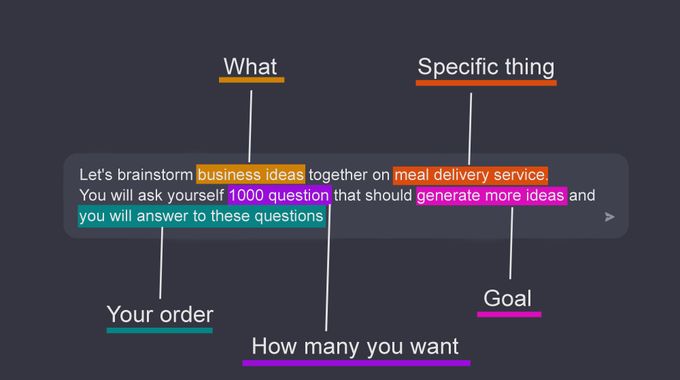 Example 2.
Example 2.
 Example 3.
Example 3.
Approach
 General system modules overview
General system modules overview
The ParlAI framework powers our conversational search model, which is built with a shared encoder, multiple decoders, a dialogue manager, and a search engine. The encoder processes input, creating hidden states that the decoders use to generate task-specific outputs. The dialogue manager and search engine work together to create meaningful, user-friendly dialogues and search results. This robust architecture, depicted as a combination of agents in the ParlAI framework, provides a powerful and intuitive conversational search experience.
Datasets and Data Generation
Table 1: Datasets Used for Training and Evaluation
| Task | Dataset | Description |
|---|---|---|
| Reasoning and intent-detection | ConvAI3 | A dataset of human-human conversations with clarifying questions |
| QReCC | An end-to-end open-domain QA dataset | |
| Question Answering | NQ | Open Domain Question Answering dataset |
| TriviaQA | 100K question-answer pairs from 65K documents from Wikipedia | |
| QuAC | Dataset for modeling, understanding, and participating in information seeking dialog | |
| Long-term memory | MSC | Multi-session chat dataset with 237k training and 25k evaluation examples |
| Internet search | WoI | Includes conversations directly grounded with knowledge retrieved from internet |
Data Preprocessing: Preparing the Learning Environment
The ConvAI3 dataset underwent a meticulous preprocessing phase to ensure it was optimized for training the dialogue generation model:
- Downloading and Unpacking: The dataset was first retrieved from its official source.
- Splitting the Data: The data was divided into designated training and validation sets for effective model evaluation.
- Data Cleaning: Duplicate entries and entries missing values were removed to ensure data quality.
- Grouping Similar Queries: Examples with identical queries were grouped together to streamline the training process.
- Converting to ParlAI format: The data was transformed into a format compatible with the ParlAI framework used for training.
Synthetic Data Generation: Expanding the Knowledge Base
To further enhance the system’s capabilities, we employed a technique called synthetic data generation. Here’s how it works:
- Leveraging GPT-3: A few examples from the preprocessed ConvAI3 dataset were fed into the GPT-3 model to establish a reference point.
- Customizing QReCC Data: Samples from the QReCC dataset were presented to the GPT-3 model, prompting it to generate corresponding entries that mirrored the structure of the ConvAI3 dataset.
- Enhancing Data Volume: GPT-3 was used to create additional data points from the QReCC dataset, further enriching the training material.
- Manual Review and Filtering: The generated data underwent a manual review process to eliminate irrelevant or nonsensical entries.
By transforming the QReCC dataset into a format compatible with ConvAI3, we were able to leverage its vast amount of data for fine-tuning the dialogue generation model. This process not only increased the training data volume but also broadened the system’s understanding of various conversational scenarios.
Table 2: Sample from ConvAI3 Preprocessed Dataset
| Text | Label Candidates | Ambiguity | Topic Description | Search Query | Answer |
|---|---|---|---|---|---|
| Find me information about diabetes education | - Which type of diabetes do you want to learn about? | 2 | I’m looking for online resources to learn and teach others about diabetes. | Find free diabetes education materials… | no |
An example prompt used for GPT-3 to generate data from the QuAC dataset in the ConvAI3 format is provided in Listing 1.
Listing 1: Example Prompt to Generate Dataset from QuaC in the format of ConvAI3 Dataset
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
Given the following example convert the target dataset into the same format as the source dataset.
Source dataset:
[
{
"index": 0,
"text": "Child support in Indiana?",
"question_candidates": ["are you interested in indiana child support", "which counties law would you like clarification on", "would you like a list of forms for processing child support claims", "would you like details on how to pay child support", "are you interested in a calculator for child support payments"],
"ambiguity": 2,
"topic_description": "Find the official legal rules and procedures pertaining to child support in Indiana.",
"search_query": "Find the official legal rules and procedures pertaining to child support in Indiana.",
"label": "convai3"
}
]
Target dataset:
{
"Context": [
"What are the pros and cons of electric cars?",
"Some pros are: They're easier on the environment. Electricity is cheaper than gasoline. Maintenance is less frequent and less expensive. They're very quiet. You'll get tax credits. They can shorten your commute time. Some cons are: Most EVs have pretty short ranges. Recharging can take a while."
],
"Question": "Tell me more about Tesla",
"Rewrite": "Tell me more about Tesla the car company.",
"Answer": "Tesla Inc. is an American automotive and energy company based in Palo Alto, California. The company specializes in electric car manufacturing and, through its SolarCity subsidiary, solar panel manufacturing.",
"Answer_URL": "https://en.wikipedia.org/wiki/Tesla,_Inc.",
"Conversation_no": 74,
"Turn_no": 2,
"Conversation_source": "trec"
}
...
Listing 2: One synthetically generated example using GPT-3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
{
"index": 0,
"text": "Tell me about electric cars",
"question_candidates": [
"What electric car do you want to know about?",
"Do you want to know about the environmental impact of electric cars?",
"Do you want to know about the cost of electric cars?",
"Do you want to know about the maintenance of electric cars?",
"Do you want to know about the noise level of electric cars?",
"Do you want to know about the tax credits for electric cars?",
"Do you want to know about the commute time with electric cars?",
"Do you want to know about the range of electric cars?",
"Do you want to know about the recharging of electric cars?"
],
"ambiguity": 2,
"topic_description": "Find information about the pros and cons of electric cars.",
"search query": "Find information about the pros and cons of electric cars.",
"label": "trec"
},
...
Training Setup
During training, the model is trained on multiple tasks simultaneously using a technique called multi-task learning. This involves optimizing the model’s parameters across all tasks by jointly minimizing a weighted sum of task-specific losses. The weights are learned during training and can be used to adjust the model’s focus on different tasks. More to it on ParlAI official documentation.
The training process is configured in a yaml file, which includes the base model, the tasks and their weights, learning rate, batch size, and other hyperparameters.
Listing 2: Abbreviated Example Training Configuration File
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
task:
fromfile:
- projects.iaia_cs.tasks.dialogue
- projects.iaia_cs.tasks.search_query
- projects.iaia_cs.tasks.augmented_convai3
- projects.iaia_cs.tasks.msc
- projects.iaia_cs.tasks.rag
multitask_weights:
- 2,1,3,2
vmt: ppl
lstep: 50
lr: 0.000001
lr_scheduler
optimizer: adamw
n_docs: 5
gradient_clip: 1.0
dropout: 0.1
attention_dropout: 0.0
init_opt: arch/r2c2_base_400M
init_model: zoo:seeker/r2c2_blenderbot_400M/model
model:
- projects.seeker.agents.seeker:ComboFidGoldDocumentAgent
The training took an average of 14 hours on 1x A5000 GPU with 24GB dedicated memory. Another model was trained on 4x A5000 GPUs using parallel training. This resulted in 2x faster training.
Three important training metrics that helped us monitor the learning curve of the AI model on general dialogue skills. As we can see, both loss and perplexity gradually decreased, while the token accuracy slightly improved during the training course.
Figure 1: Performance metrics for dialogue generation model trained on the ConvAI3 dataset with guidance from a ParlAI teacher
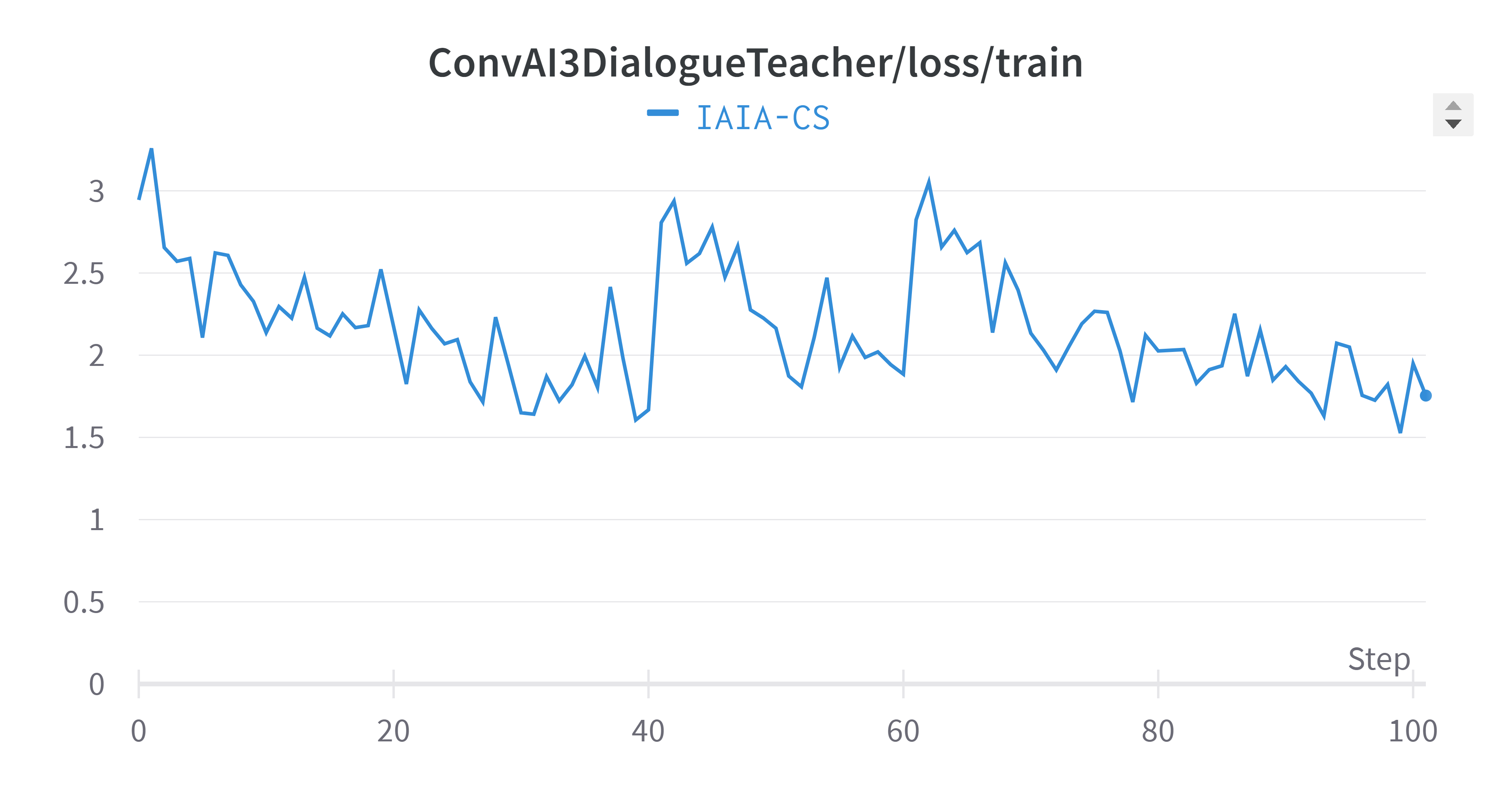 |  |
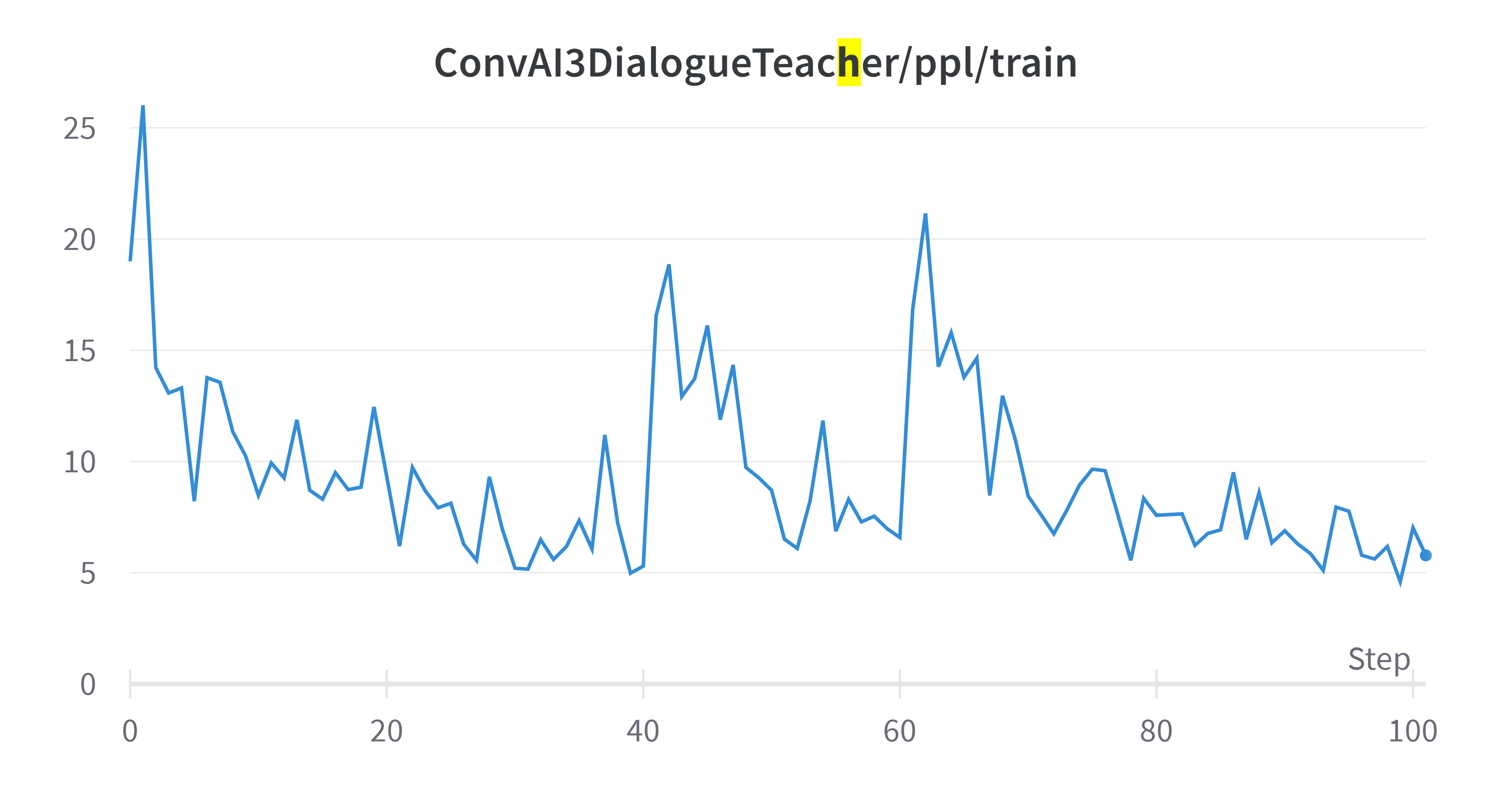 | 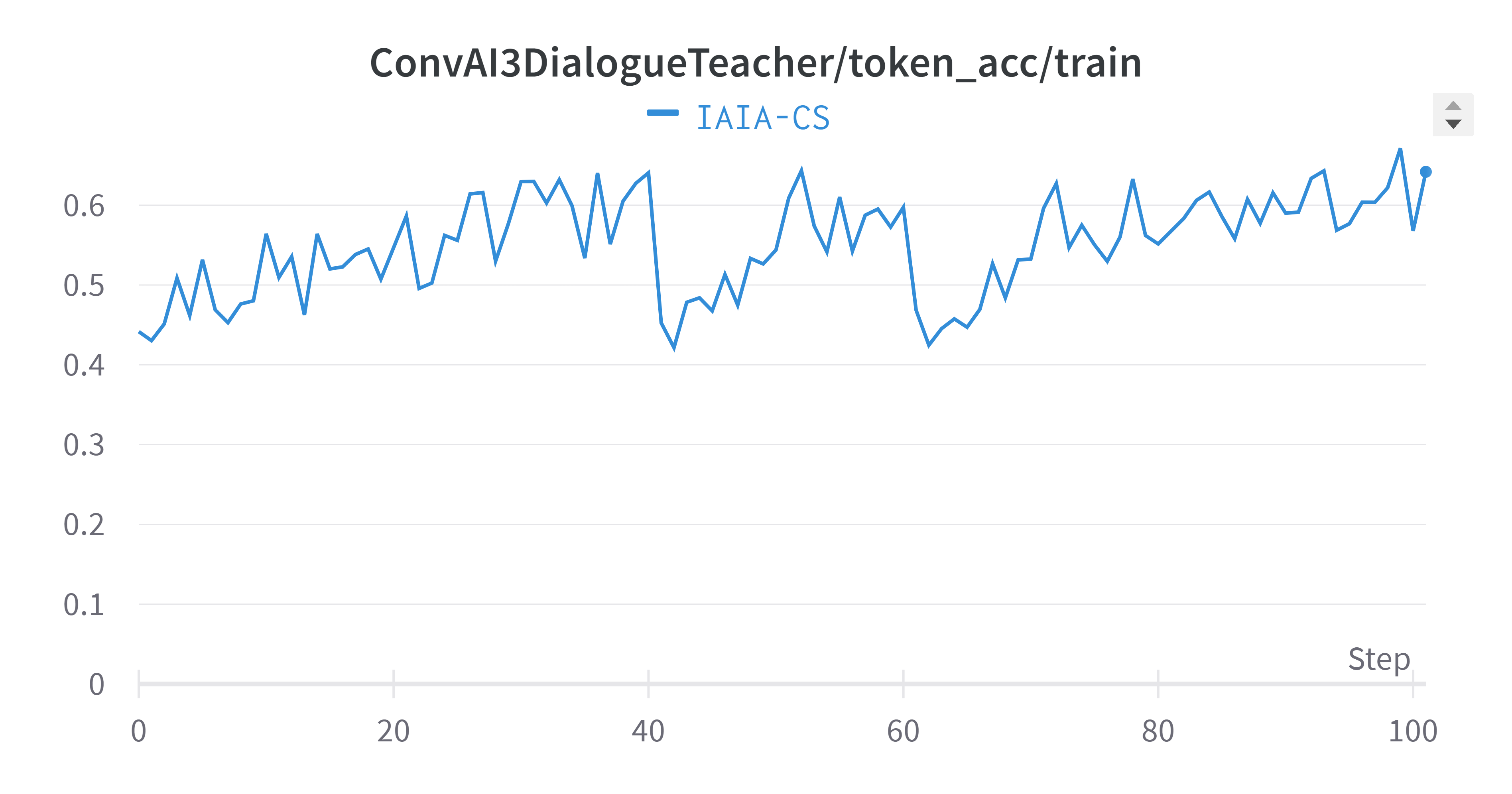 |
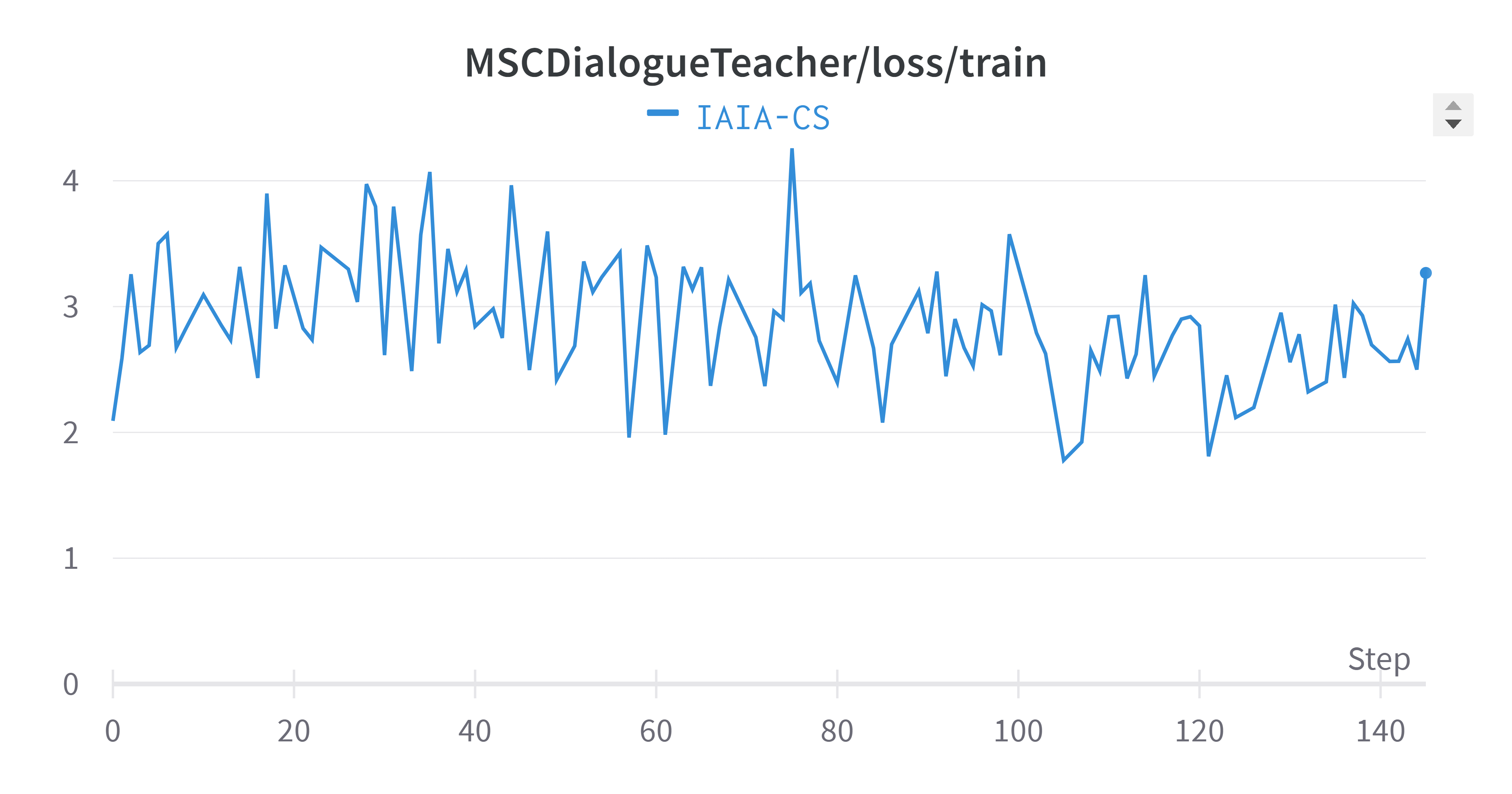
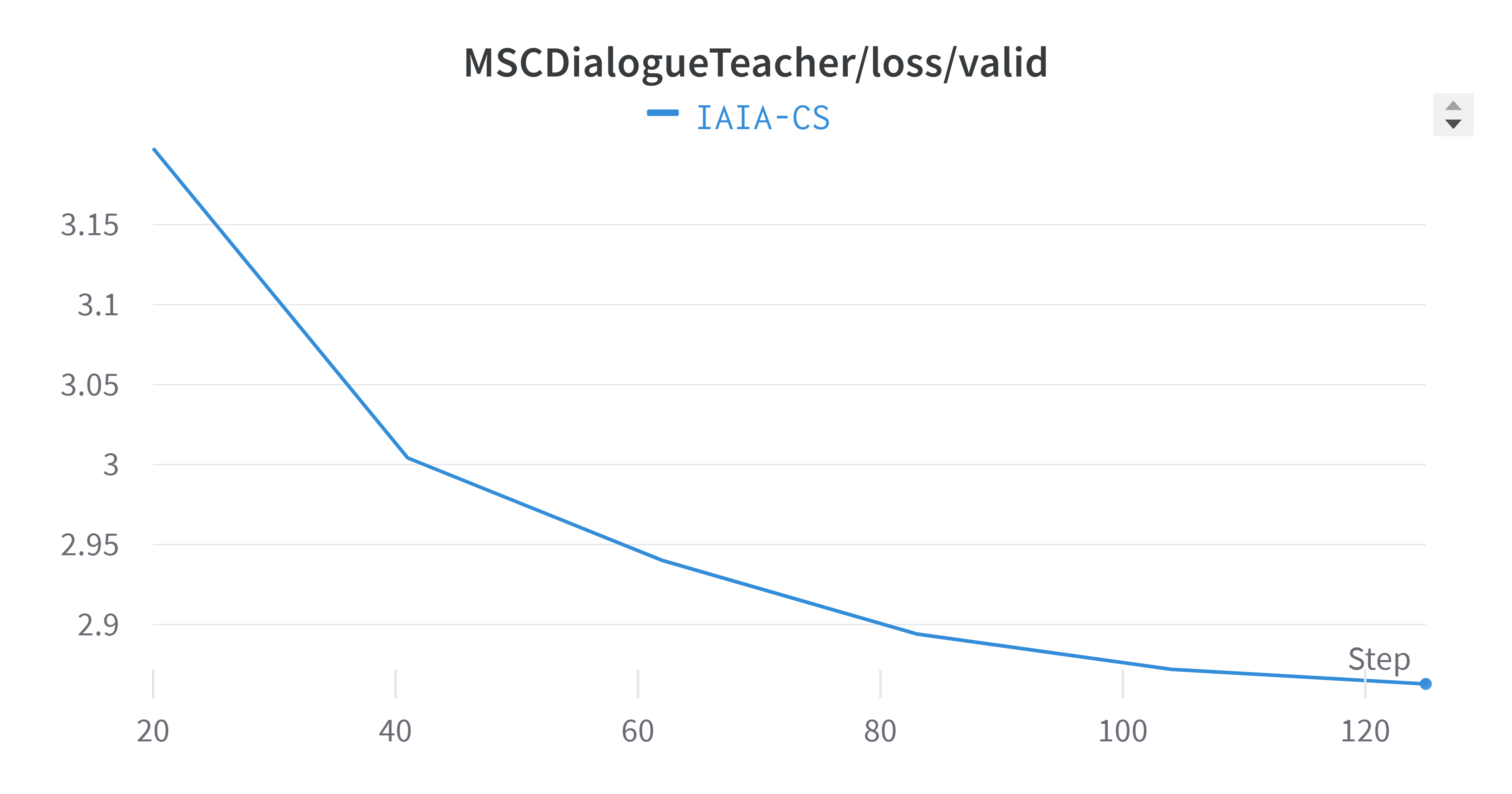
The next figure depicts the training process of the multi-session chat task handler. This task is responsible for storing and retrieving context from the memory module. As we can see, the loss dropped while the token accuracy constantly kept improving in the validation phase.
Figure 2: Performance Metrics for Multi-Session Chat Task in 2 columns table
 |  |
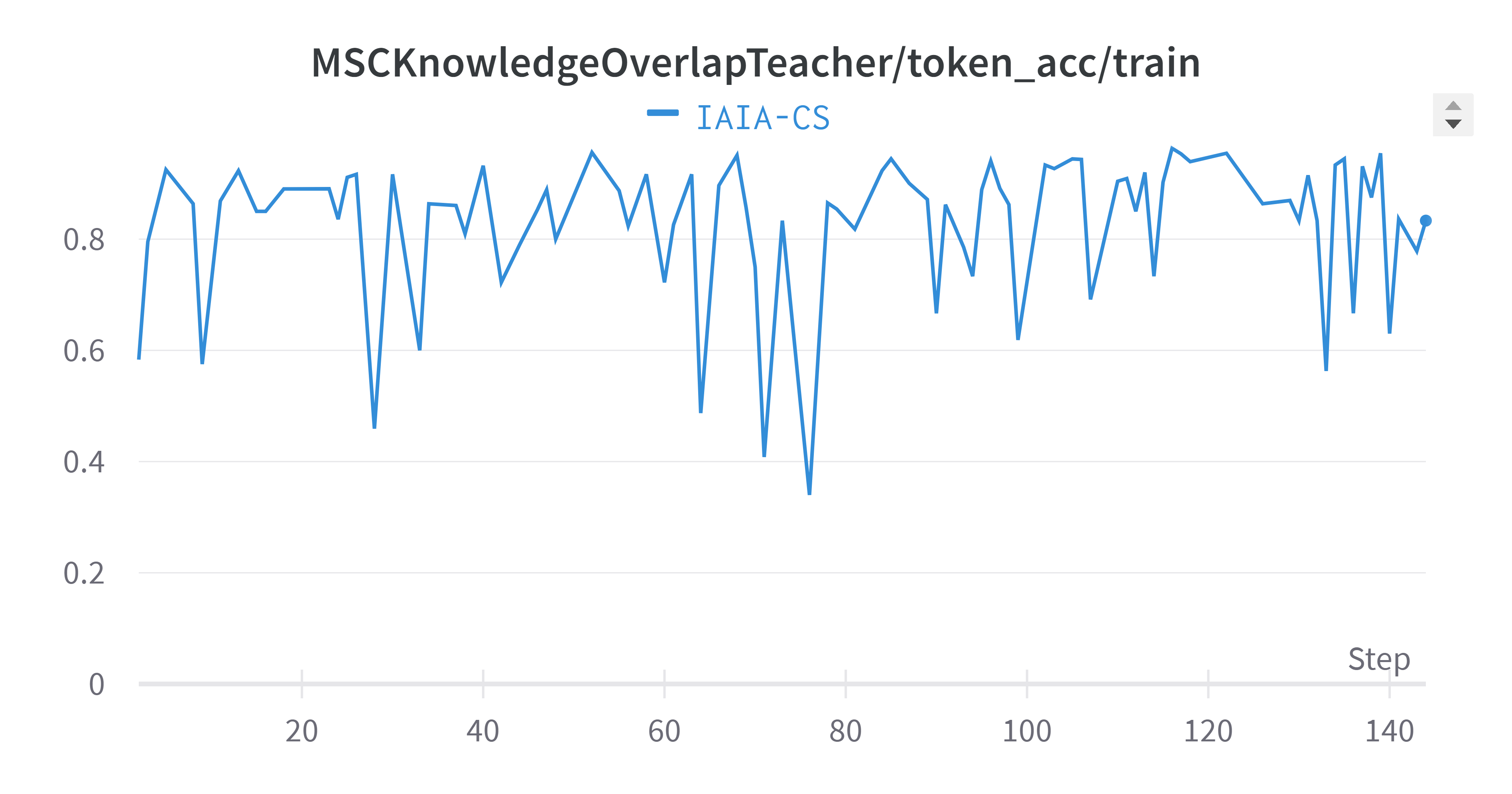 | 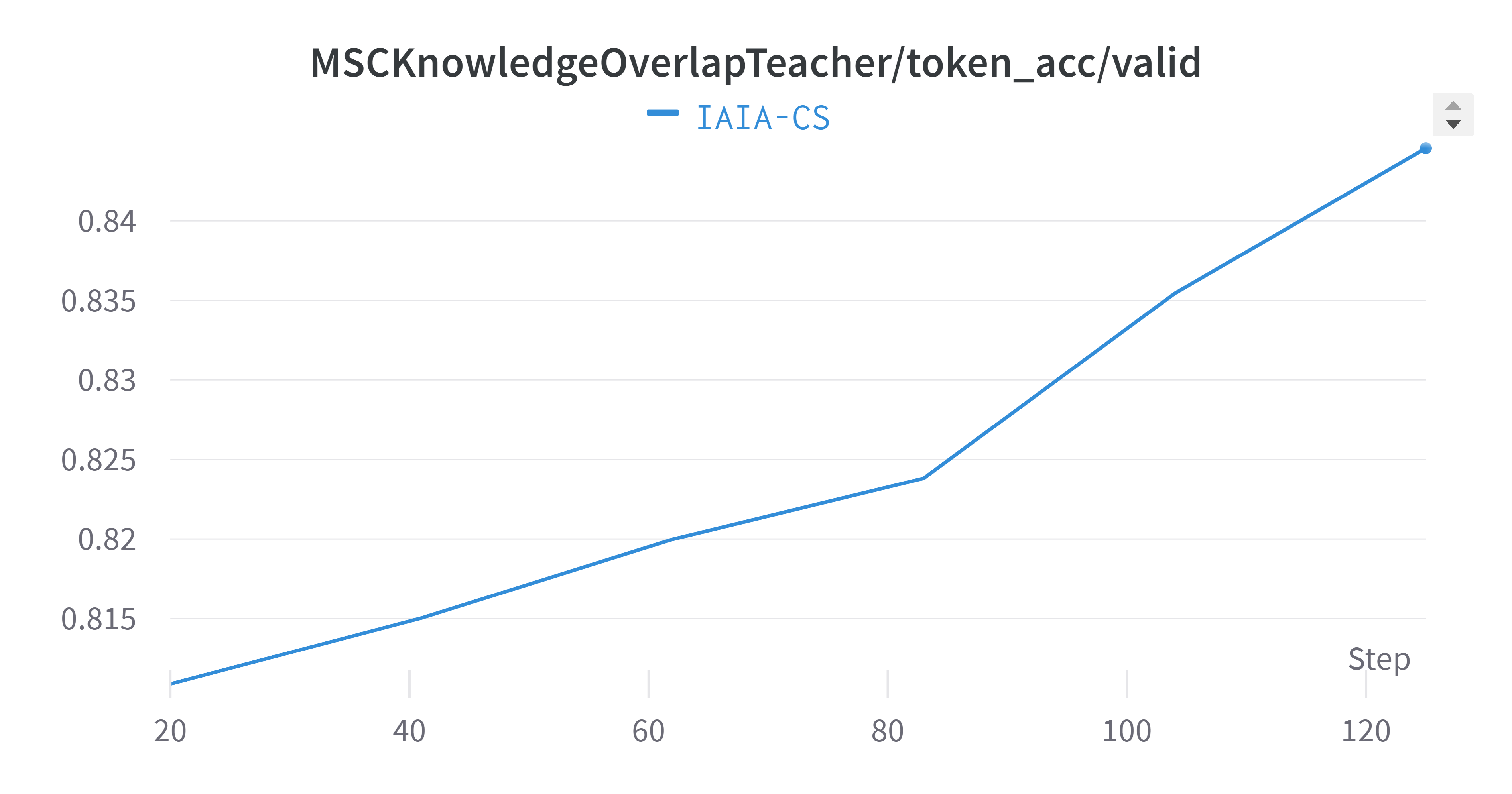 |
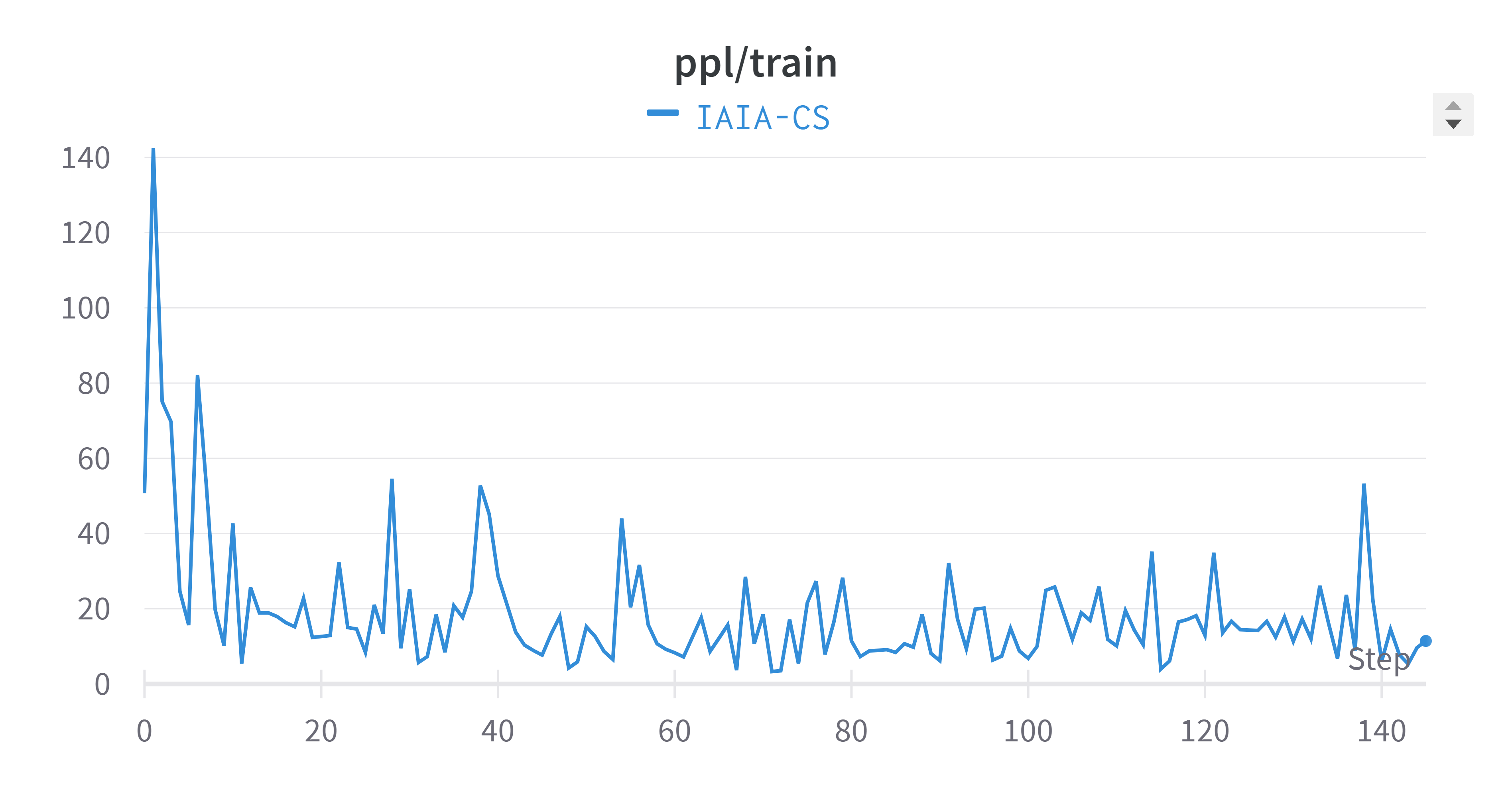
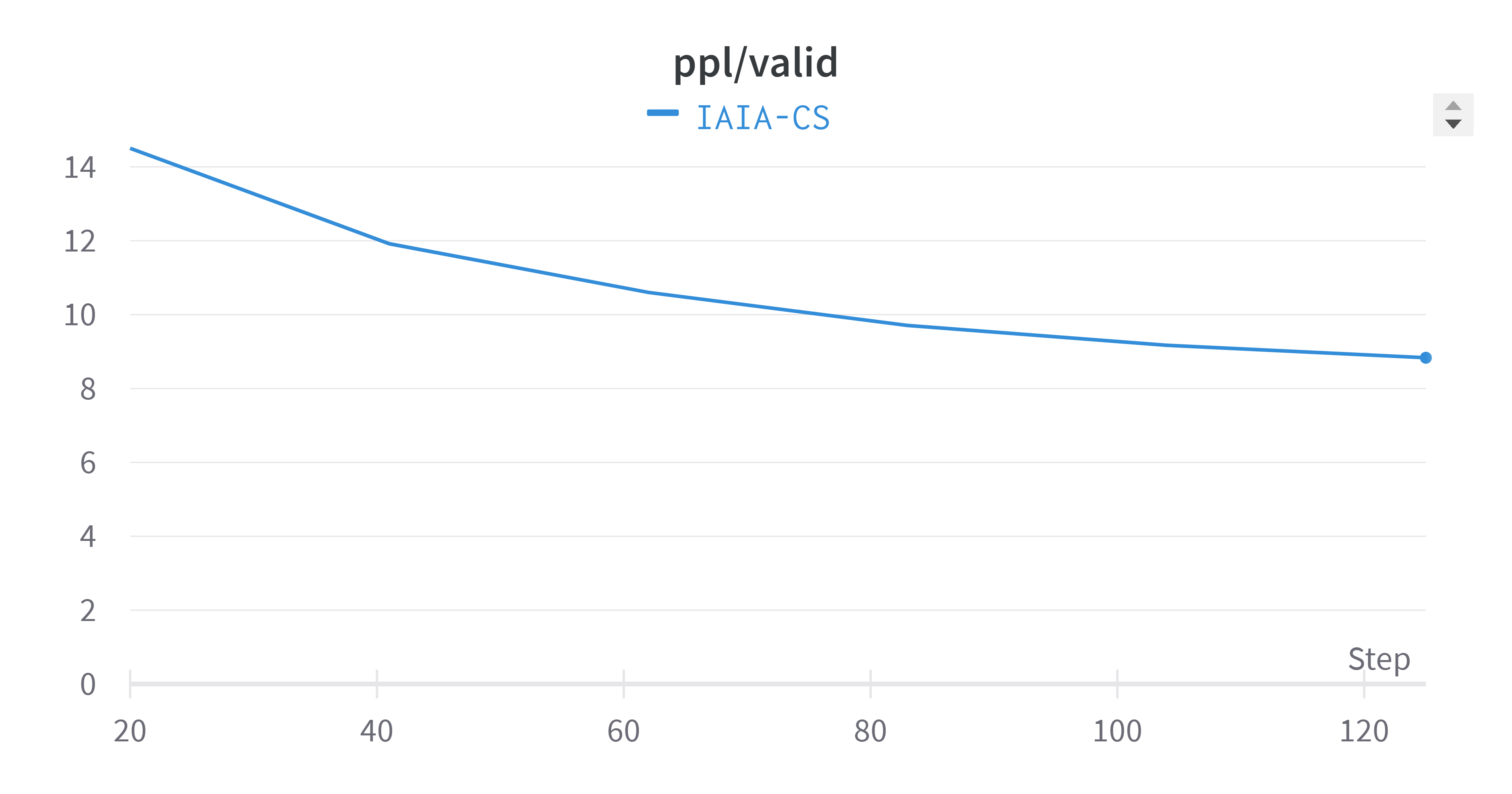
Finally, Figure~\ref{fig:training-plots} combines and averages the metrics across all tasks. The averaged validation perplexity value showed a slight improvement (lower is better) compared to each task separately. It’s important to note that training plots often exhibit oscillation, which is a natural part of the model’s learning process as it adjusts weights to minimize the loss function.
Figure 5: Overall Performance Perplexity
 |  |
Qualitative Evaluation
Demo 1: Cached Intent Modeling and Knowledge Expansion
Figure 6: Example of a dialogue between the user and the final AI system with geo-location = Germany
| Turn | Dialogue | Turn | Search Server |
|---|---|---|---|
| 1 |  | 2 |  |
| 3 |  | 4 | 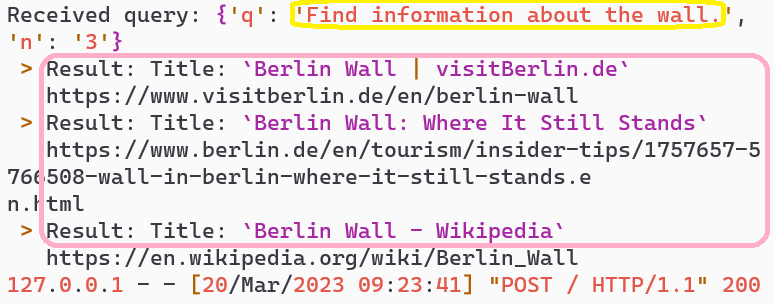 |
| 5 | 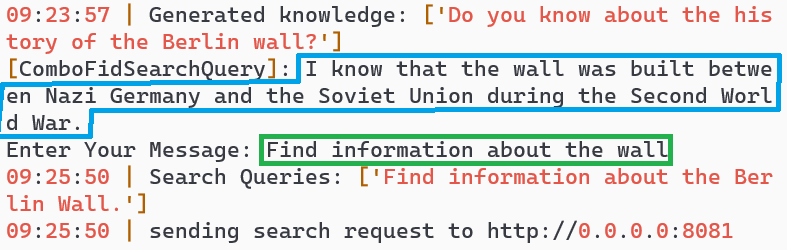 | 6 |  |
| 7 | 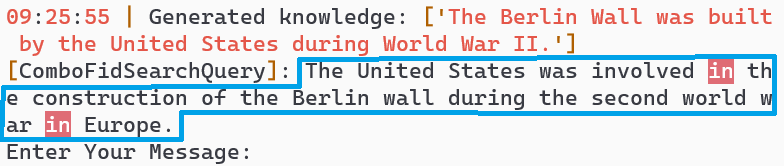 | 8 | end |
Intention Clarification
- User Request: The user types an ambiguous request “find information about the wall” (turn 1).
- AI Response: The AI system responds by asking “Do you want to know more about the Berlin wall?” (turn 3 blue).
- Dialogue Control: The model uses context and learned task representations to decide on a task and generate a response.
Knowledge Expansion
- User Confirmation: The user acknowledges the model’s predicted intention (turn 3 green).
- Search Query: The AI generates a search query, fetches results, and responds with Berlin Wall information (turns 4-5).
Testing Cached Intent Modeling
- Repeated Query: The user repeats the question, and the model understands the intent without clarification, providing new Berlin Wall information (turns 5-7).
Observations:
- Hallucination Risk: The model occasionally produces false information from search results.
- Adaptive Intent Understanding: The model switches between search and memory access based on context.
- Geo-bias: The AI’s understanding is influenced by the search server’s geo-location.
Demo 2: Disambiguation and Correction of the Model’s Understanding
Figure 7: Example of a dialogue between the user and the final AI system with geo-location = USA
| Turn | Dialogue | Turn | Search Server |
|---|---|---|---|
| 1 |  | 2 | 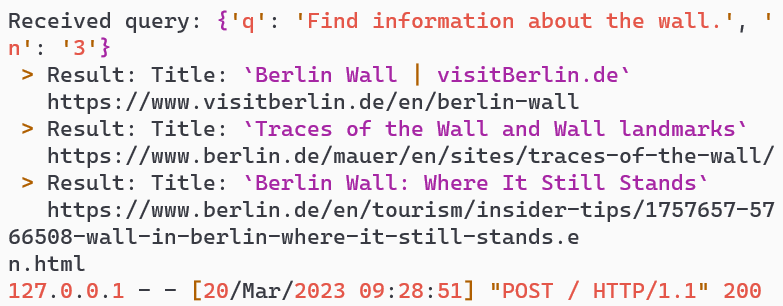 |
| 3 | 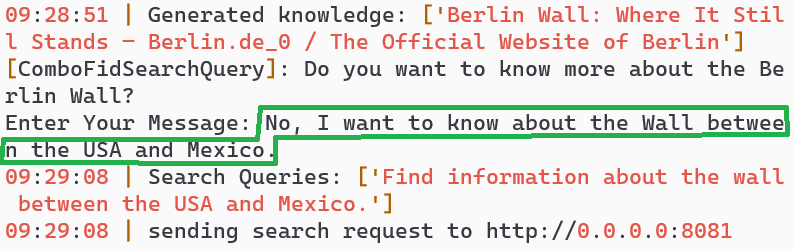 | 4 |  |
| 5 |  | 6 | end |
Disambiguation and Correction
- User Clarification: The user claims the model misunderstood and provides additional information (turn 3 green).
Adaptive Intent Understanding
- Modified Query: The AI adjusts the search query based on new information and responds with information about the Wall between Mexico and the USA (turns 4-5).
Conclusion
By demonstrating these two scenarios, we can see that our proposed AI is capable of understanding complex user intent and adapt its understanding throughout the dialogue history in order to respond with contextually coherent answers.
Quantitative Evaluation
To evaluate our conversational search model, we employed several metrics for a comprehensive quantitative comparison: BLEU, ROUGE, f1, precision, recall, and perplexity. These metrics were selected to gauge the quality of the model’s generated responses in terms of relevance and fluency.
The evaluation utilized the ConvAI3 dataset’s validation split as a benchmark. The ParlAI framework streamlined the evaluation process, as illustrated below:
1
2
3
4
5
6
7
8
9
10
11
12
13
eval_model:
task:
- projects.IAIA_CS.tasks.knowledge
- projects.IAIA_CS.tasks.dialogue
- projects.IAIA_CS.tasks.search_query
model_file: IAIA_CS/model
report_filename: IAIA_CS.json
metrics: ppl,f1,accuracy,rouge,bleu
num_examples: 10
overrides:
opt: parlai/opt_presets/gen/IAIA_CS_dialogue.opt
multitask_weights: 3,3,1
search_server: http://localhost:8081
Quantitative Results
We compared our model’s performance with two state-of-the-art internet-augmented conversational search models, Blenderbot 2 and Seeker, across various standard NLP metrics. Two versions of our model were evaluated: one with and one without DHGT-based dialogue summarization, both having 400 million parameters.
Table~\ref{tab:comparison_different_models}: Comparison of Metrics for Different Models
| Model | Precision | Recall | f1 | Perplexity | BLEU-1 | BLEU-2 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|---|---|---|---|---|---|
| BB2 (400M) | 0.059 | 0.158 | 0.08 | 49.86 | 0.059 | 0.019 | 0.158 | 0.06 | 0.125 |
| Seeker (400M) | 0.078 | 0.262 | 0.112 | 27.87 | 0.078 | 0.009 | 0.26 | 0.05 | 0.229 |
| Ours (400M) | 0.122 | 0.416 | 0.173 | 22.36 | 0.122 | 0.046 | 0.416 | 0.04 | 0.375 |
| Ours (DHGT) | 0.106 | 0.42 | 0.156 | 56.07 | 0.02 | 0.000 | 0.33 | 0.01 | 0.12 |
Observations
- Our model surpasses the state-of-the-art models in precision, f1 score, and perplexity.
- Our BLEU-1 and BLEU-2 scores are superior to those of Blenderbot 2 and Seeker.
- The DHGT-based dialogue summarization model underperforms by approximately 30% across all metrics, possibly due to shorter dialogues.
Discussion
Our model’s superior performance is attributed to its fine-tuning for ambiguous user queries and the dataset’s focus on convAI3, which targets ambiguous user queries. Blenderbot 2 emphasizes casual conversations, while Seeker prioritizes relevant results without questioning user intent, resulting in inferior performance with ambiguous queries.
Knowledge graphs and heterogeneous graph transformers are emerging technologies with untapped potential in conversational search models. Short dialogues may not benefit from DHGT-based summarization due to context and intent capture challenges. Performance of these models is data-dependent and expected to improve with more data and larger model size. Future work will focus on data incorporation and DHGT model refinement.
On the other hand, utilizing synthetic data generation techniques to expand the training dataset has proven to be an effective strategy for enhancing the model’s understanding of ambiguous user queries. This approach has significantly improved the model’s performance across various metrics, demonstrating its potential to revolutionize conversational search systems.