
Introduction
Most businesses are transitioning from a traditional static IT infrastructure to a dynamic mix of on-premises, managed public/private cloud environments powered by virtualized or software-defined resources that can be scaled and modified on the fly.
Every day, the applications and systems in these contexts generate massive amounts of data. As a result, traditional IT management solutions are unable to keep up with the volume, meaning they can’t sort out the important events from the stream of mixed data and they can’t provide the real-time insights and predictive analytics that IT operations teams need to respond to issues quickly enough to meet service demand expectations.
Artificial Intelligence for IT Operations (AIOps) is a combination of AI technologies and data analytics to automate key tasks and suggest solutions for common IT issues in software operations, such as unexpected downtime or unauthorized data access. AIOps is being introduced in many industrial applications such as anomaly detection, intrusion detection, root cause analysis, incident classification and autonomous decision making.
However, applying AI -namely deep learning- exposes the system to a different type of security threats, namely adversarial attacks. A malicious attacker could cause severe damage to the infrastructure under the control of an ML model by feeding perturbed input into a machine learning model that is deliberately designed to cause misclassification. These manipulations on the input usually appear unmodified to human observers.
In this article, we provide a comprehensive explanation about adversarial attacks and their potential impact on AIOps solutions in fields such as Internet of Things (IoT) and edge computing. We review some existing examples of adversarial attacks in areas such as edge computing and IoT applications. We then discuss some challenges and possible solutions. A general analysis of adversarial attacks on AIOps is presented in Section II. We discuss some possible and existing attack scenarios in Section III. A survey on existing work and methods to defend against AAs are given in Section IV, followed by a conclusion in Section V.
Background
In AIOps, time series data (logs, error reports, performance metrics, etc.) are used to monitor and manage infrastructures and the applications that are built upon them. AI, for instance, helps cloud service providers manage resources dynamically and sometimes fully autonomously through time series classification TSC, and deep learning methods and analytics help determine how to distribute and manage the load balance between edge computing nodes. AI and deep learning are also being introduced in areas such as industrial control and medicine (Fawaz et al., 2018). They are also used in power consumption monitoring (Shafiq et al., 2020). Recent researches state that deep learning proved to be effective in classifying time series data.
However, and because DNNs are prone to adversarial attacks, by adding small perturbations to the original time series, adversarial examples can lead to huge recognition errors. Generally, deep learning models are prone to making errors when applied to such fields due to data noise and data manipulations.
Most of current machine learning models are vulnerable to adversarial examples (Szegedy et al., 2013). By using adversarial examples, it is possible to identify weaknesses in the training algorithm, which can lead to improved performance overall. Cyber attackers could, by contrast, utilize adversarial examples to cause damage to IT infrastructure.
The figure below from \cite{gupta2021responsible} illustrates how adversarial manipulation can occur on a system that runs on ML, categorizing these potential attacks into five points:
- Physical world such as changing stop signs that a
CAMera sees. - Manipulating an I/O device such as replacing a sensor feeding data to the system with a faulty one.
- Perturbing the data in digital form, whether as input in the network stage or from the ML model at the output stage.
- Modifying the input data at the internal system.
- Changing the ML model architecture.
 Generalized adversarial attack points on ML model
Generalized adversarial attack points on ML model
Among the most commonly debated causes of neural network vulnerabilities, researches suggest that the non-linearity of deep neural networks, in combination with the inadequacy of model averaging, may be the main reason. Several ways can be used to disrupt machine learning models’ decision. we can define them into three basic types according to (Dasgupta et al., 2020):
- Poisoning attack: It happens during training time when the data fed to the ML model is changed.
- Evasion attack: It occurs during production when inputs are changed leading to the misclassification of outputs into different targeted or random groups.
- Trojan AI Attack: This AI Trojan attack changes the architecture in a way that results in a misclassification of input. It can happen during setup/transfer of machine learning models to the system or at runtime.
Research on adversarial attacks in AIOps focuses more on evasion attacks, because they occur in systems that look to the attackers as a black box, and because most of the risk associated with AI managing distributed systems lies in these attacks in the production stage after the model has been trained.
Adversarial attacks in IoT: methods and example
In this section we review some of the adversarial attack methods in details, more specifically the attack methods that affect DNNs with time series as input.
Fast Gradient Sign Method (FGSM)
The FGSM is one of the most famous methods to generate adversarial examples. It was first introduced by (Goodfellow et al., 2014) to generate adversarial images that fool Google’s famous model ImageNet to predict the wrong class with a very high confidence of 99.3%. According to Goodfellow et al., the FGSM involves adding non-random noise of the same direction as the gradient of the cost function in relation to the data.
As a result of the linear design of the model, the influence of disturbance in the neural network will gradually grow larger. This is the underlying reason for FGSM attacking the neural network. Furthermore, ReLU is a kind of linear activation function in neural networks, which tends to make the whole network linear. Additionally, the more dimensions of input, the more at risk for adversarial attacks the model will be. This method is also used to generate adversarial examples against ML models that perform time series classification TSC (Fawaz et al., 2019) as in the figure below.
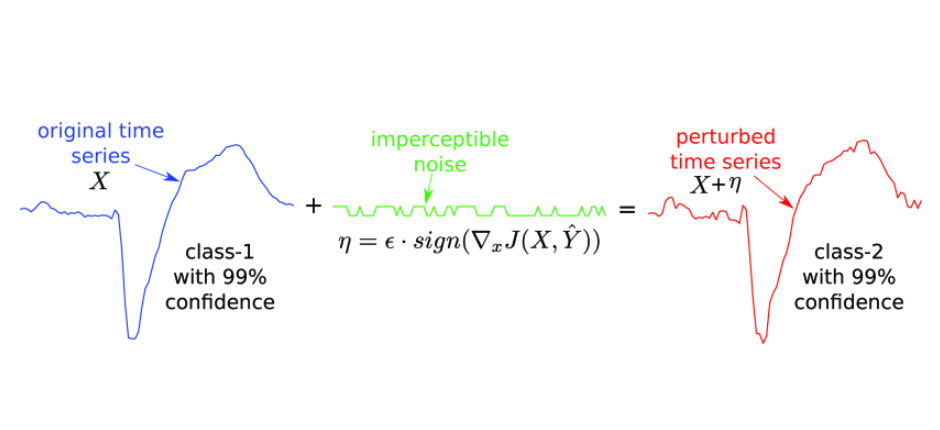 A fast gradient sign method (FGSM) example of perturbing the classification of input time series by adding imperceptible noise (Fawaz et al., 2019)
A fast gradient sign method (FGSM) example of perturbing the classification of input time series by adding imperceptible noise (Fawaz et al., 2019)
Basic Iterative Method BSC
The BIM is a more advanced version of the FGSM. It is an iterative method that adds a small perturbation to the input data at each iteration. The perturbation is calculated by adding the gradient of the loss function to the input data. The perturbation is then clipped to a certain range to ensure that the perturbed data is still within the range of the original data. The process is repeated until the perturbation reaches a certain threshold.
This method generates adversarial samples that are closer to original samples and have a better chance of fooling a network by adding smaller changes in an iterative fashion.
GAN-based attacks
Generative adversarial networks GANs (Goodfellow et al., 2020) are a class of machine learning models that are used to generate new data that is similar to the training data.
They are composed of two networks: a generator and a discriminator. The generator is used to generate new data, and the discriminator is used to distinguish between the generated data and the real data. The generator is trained to fool the discriminator, and the discriminator is trained to distinguish between the generated data and the real data.
GANs were first proposed for the generation of adversarial samples by (Xiao et al., 2018). An adversarial distribution is learned by training a generator to maximize the target adversarial loss and the GAN loss. The distance between adversarial example samples x’ and benign samples x is constrained by using a soft hinge loss as a penalty. However, if the target classifier’s outputs are used along with the distillation model, the attack reduces the accuracy of the MadryLab’s MNIST secret model to 92.74% (Madry et al., 2017), making it one of the best black-box attacks in terms of results.
Random Noise Attack
A new kind of attack has been discovered by (Nguyen et al., 2015) called false positive attack, which involves deep neural networks misclassifying adversarial attacks with up to 99% confidence.
Another work \cite{yang2021iot} trained a ResNet model to classify a time series data set along with some random noise data. With low confidence in the classifier, random time series data are invariably rejected. Nevertheless, the random noise data classified as class two were classified with a high degree of confidence, which proves that the model poses a risk when deployed in real applications. The figure \ref{rna} shows a simple illustration of how random noise can be used against a trained model being deployed into the industry.
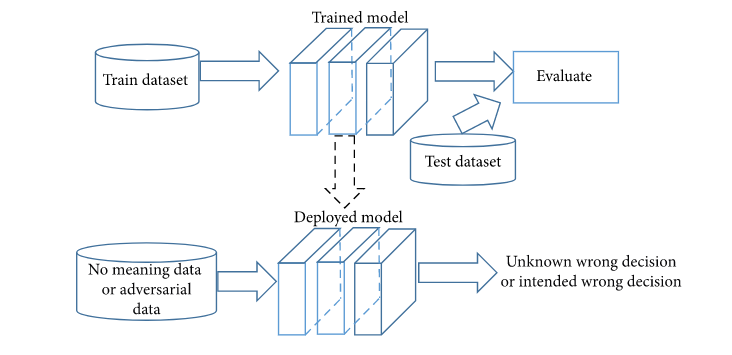 An overview of the models that are trained and the threats associated with IoT devices.
An overview of the models that are trained and the threats associated with IoT devices.
Countermeasures and mitigation
(Yuan et al., 2019) divides the ways adversarial attacks are countered in two ways:
- Reactively identifying: the disrupted instance: one reactive technique is to detect adversarial examples during testing. The detectors, however, may still be susceptible to attacks designed to fool them.
- Proactively increasing: the network’s robustness without creating examples: One of the most effective ways of improving the neural network’S defense is by (re)training the classifier with adversarial examples.
There are many methods that can help counter or at least reduce such attacks. These defensive techniques include low-pass filters, data compression, model structure modification, network verification, and soft thresholds (Gupta & Dasgupta, 2021). An ML can also be trained in a way to give output probabilities as a vector representing all classes, rather than the choice of a class.
In this section we review some methods used to identify adversary weaknesses in neural networks that perform time series classification and help building their defense against adversarial attacks by generating adversarial examples.
Adversarial training
The adversarial training method is an intuitive defence against adversarial samples. Several adversarial examples are provided and used explicitly to train the model to not be fooled by them all. According to (Ren et al., 2020) it can be formulated as a min–max game between the attacker and the defender. The attacker aims to generate adversarial examples that are misclassified by the defender, while the defender aims to minimize the misclassification rate of the attacker.
This technique has the disadvantage that we need to retrain the model whenever new attack samples are discovered. Adversarial training also reduces the accuracy of the ML model and exposes it to generalization.
Class Activation Map and Adversarial Examples
A class activation map is a simple technique that is used to get the discriminative regions used by a CNN to identify a specific class in an image, letting us see which regions in an image for example were relevant to this class. This shows that deep learning networks have an attention mechanism built in to them.
A work published by (Wang et al., 2017) proposes the use of CAM in time series analysis by highlighting the susceptible area of the data in one-dimensional form. Therefore, the susceptible fields of the time-series data are continuously distributed, allowing a preprocessing technique to potentially improve the robustness of the model.
To use the CAM technique, the network architecture must have a global average pooling layer after the final convolutional layer, and then a linear (dense) layer. Therefore, this technique cannot be applied to existing networks that lack this structure.
Encode-decode joint training
(Yang et al., 2021) proposed a robust IoT data classification model based on an encode-decode joint training model. This encode-decode model is used to reconstruct original time series examples through a thermometer encoding applied to the original training examples.
The method is divided into two parts: one is the encode-decode model, and the other is a traditional deep neural network model for classification. Decoding the time series yields the original time series recovered from its thermometer encoding forms. Using this encode-decode model allows us to remove some noise and adversarial perturbations from a linear gradient sign system by using its nonlinear transforms.
The figure below shows the architecture of the proposed model.
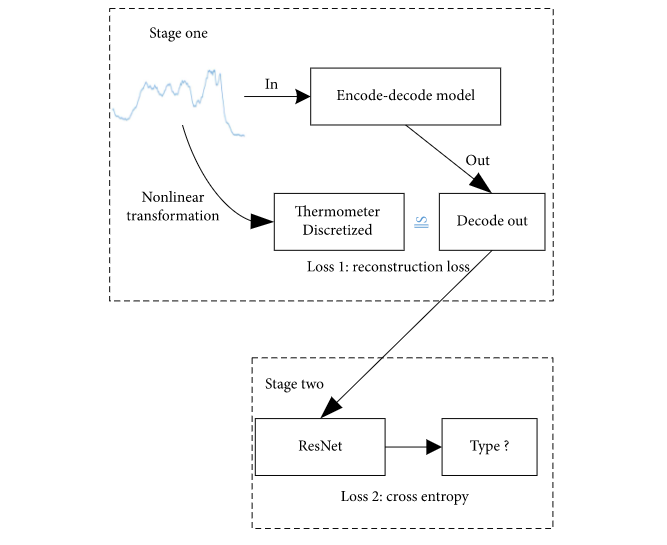 The schema of the proposed method by (Yang et al., 2021)
The schema of the proposed method by (Yang et al., 2021)
To test the efficacy of their proposed work, adversarial time series examples were generated using FGSM method in order to attack their model that is trained on Coffee dataset. To compare the results, another ResNet model is implemented without the encoder-decoder part and trained on the same dataset. The next figure shows that the encode-decode model improves the accuracy of attacks by the FGSM.
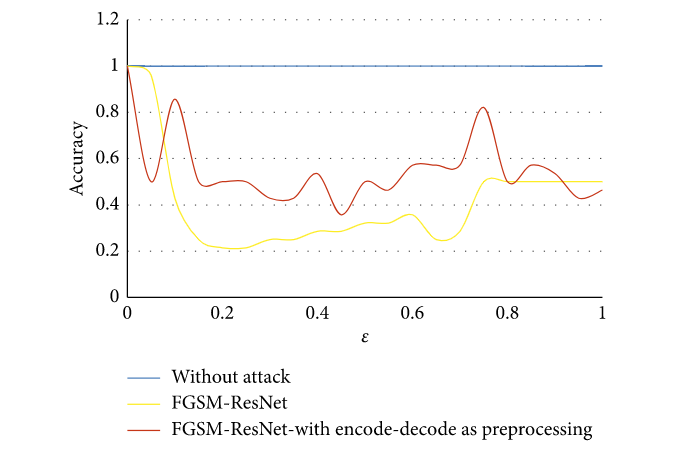 The accuracy results of the Coffee dataset when used with the encode-decode model as a preprocessing method for defense
The accuracy results of the Coffee dataset when used with the encode-decode model as a preprocessing method for defense FGSM attacks
Conclusion
In this article, we examined the importance of building neural networks models that are resistant to adversarial examples, and illustrated the dangers adversarial attacks pose in the IoT domain and AIOps in general.
Following that, we discussed a few examples of adversarial attack methods and reviewed some state-of-the-art research to help fight them.
Modelling in a linear way is easy to train, while using nonlinear effects to resist adversarial perturbation is challenging. Alternatively, more powerful optimization methods could be developed in the long run that would be able to train nonlinear models faster and easier without a trade-off.
(Goodfellow et al., 2014) argues, that deep networks are not as vulnerable to adversarial examples as shallow linear models, since they at least provide representations of functions that can survive adversarial perturbation. It is demonstrated by the universal approximator theorem (Hornik et al., 1989) that any function can be represented accurately by a neural network if its hidden layer has enough units. (Goodfellow et al., 2014) give a thumb rule, where easy-to-optimize models are easy to perturb and that RBF networks are resilient to adversarial examples, yet may be overly complex.
In addition, different trained models perform differently against the same attack, making it difficult to determine the quality of the model. There are no theoretical studies on how to measure the goodness or robustness of a trained model. In light of the accelerating interest in IoT data analysis using deep learning, more research is still needed to explore how to interpret deep learning models. (Gupta & Dasgupta, 2021)
The use of deep learning in fully autonomously managing IoT systems, especially in safety-critical applications, will be too risky until we have enough knowledge of adversarial attacks and how to build a highly robust ML models.
References
- Fawaz, H. I., Forestier, G., Weber, J., Idoumghar, L., & Muller, P.-A. (2018). Evaluating surgical skills from kinematic data using convolutional neural networks. International Conference on Medical Image Computing and Computer-Assisted Intervention, 214–221.
- Shafiq, M., Tian, Z., Bashir, A. K., Du, X., & Guizani, M. (2020). CorrAUC: a malicious bot-IoT traffic detection method in IoT network using machine-learning techniques. IEEE Internet of Things Journal, 8(5), 3242–3254.
- Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., & Fergus, R. (2013). Intriguing properties of neural networks. ArXiv Preprint ArXiv:1312.6199.
- Dasgupta, D., Akhtar, Z., & Sen, S. (2020). Machine learning in cybersecurity: a comprehensive survey. The Journal of Defense Modeling and Simulation, 1548512920951275.
- Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and harnessing adversarial examples. ArXiv Preprint ArXiv:1412.6572.
- Fawaz, H. I., Forestier, G., Weber, J., Idoumghar, L., & Muller, P.-A. (2019). Adversarial attacks on deep neural networks for time series classification. 2019 International Joint Conference on Neural Networks (IJCNN), 1–8.
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2020). Generative adversarial networks. Communications of the ACM, 63(11), 139–144.
- Xiao, C., Li, B., Zhu, J.-Y., He, W., Liu, M., & Song, D. (2018). Generating adversarial examples with adversarial networks. ArXiv Preprint ArXiv:1801.02610.
- Madry, A., Makelov, A., Schmidt, L., Tsipras, D., & Vladu, A. (2017). Towards deep learning models resistant to adversarial attacks. ArXiv Preprint ArXiv:1706.06083.
- Nguyen, A., Yosinski, J., & Clune, J. (2015). Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 427–436.
- Yuan, X., He, P., Zhu, Q., & Li, X. (2019). Adversarial examples: Attacks and defenses for deep learning. IEEE Transactions on Neural Networks and Learning Systems, 30(9), 2805–2824.
- Gupta, K. D., & Dasgupta, D. (2021). Who is Responsible for Adversarial Defense? ArXiv Preprint ArXiv:2106.14152.
- Ren, K., Zheng, T., Qin, Z., & Liu, X. (2020). Adversarial Attacks and Defenses in Deep Learning. Engineering, 6(3), 346–360. https://doi.org/https://doi.org/10.1016/j.eng.2019.12.012
- Wang, Z., Yan, W., & Oates, T. (2017). Time series classification from scratch with deep neural networks: A strong baseline. 2017 International Joint Conference on Neural Networks (IJCNN), 1578–1585.
- Yang, Z., Abbasi, I. A., Algarni, F., Ali, S., & Zhang, M. (2021). An IoT Time Series Data Security Model for Adversarial Attack Based on Thermometer Encoding. Security and Communication Networks, 2021.