
Introduction
In this post, we will be implementing a simple recommender system using the BERT4Rec model, which is a BERT-based model for sequential recommendation. The model is based on the paper BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer by Zhen-Hua Ling, et al. The model is a simple BERT model with a few modifications to make it suitable for sequential recommendation. The model is trained on the MovieLens 1M dataset.
Autoregressive Language Modeling
Before we get into details about BERT4Rec we need to understand what autoregressive model means. An autoregressive model is a model that generates the next token in the sequence based on the previous tokens in the sequence. For example, if we have a sequence of tokens [I, like, to, watch, movies], the model will generate the next token based on the previous tokens. A sequence could contain words or numbers or anything else.
Most language models, recommender systems, time-series forecasting models, and many other models are autoregressive models. The model generates the next token based on the previous tokens in the sequence.
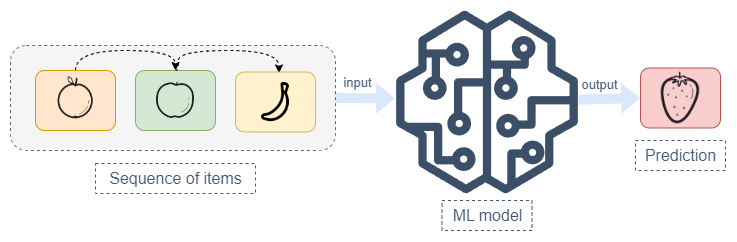 A simplified illustration of how autoregressive models work
A simplified illustration of how autoregressive models work
BERT4Rec
BERT4Rec is a variant of the BERT (Bidirectional Encoder Representations from Transformers) model that is specifically designed for use in recommendation systems. The original BERT model is a general-purpose language model that can be used for a variety of natural language processing tasks, including text classification, machine translation, and question answering. The model is based on the paper BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer by Zhen-Hua Ling, et al. The model is a simple BERT model with a few modifications to make it suitable for sequential recommendation. The model is trained on the MovieLens 1M dataset.
BERT4Rec is different from the original BERT model in a few key ways:
- BERT4Rec is trained on a large dataset of user-item interactions, such as clicks or purchases, whereas the original BERT model is trained on a dataset of unstructured text.
- BERT4Rec uses a special type of attention mechanism called “next item prediction” that allows it to model the sequential nature of user-item interactions. This allows it to make more accurate recommendations based on the items that a user has interacted with in the past.
- BERT4Rec uses a special loss function that encourages it to make more diverse and personalized recommendations. This helps to avoid the problem of “cold start” where the model struggles to make recommendations for users with little or no interaction history.
Overall, BERT4Rec is designed to be more effective at modeling and predicting user-item interactions than the original BERT model, which makes it better suited for use in recommendation systems.
What makes BERT4Rec different from the classic BERT is that BERT4Rec’s vocabulary isn’t words but rather ids of items in the sequence. So, a sequence of items, for example movies [“Harry Potter”, “Silence of the lambs”, …] would be represented as a sequence of ids [4, 8, 15, 32, 100]. There are two separate embedding layers, one for items and one for user ids.
BERT4Rec architecture. Image credit: Zhen-Hua Ling, et al.
Implementation
Dataset preparation
The dataset we will be using is the MovieLens 1M dataset. The dataset contains 1 million ratings from 6000 users on 4000 movies. The dataset is available in the MovieLens 1M website. The dataset is available in the form of a zip file. We will be using the ratings.dat file from the dataset. The ratings.dat file contains the following columns:
UserIDMovieIDRating
The dataset needs to be preprocessed and converted into a format that is suitable for training. The preprocessing steps are as follows:
- Sort the dataset by
Timestamp - Get the
UserIDandMovieIDcolumns - Split the dataset into train and valuation sets
- Convert the
UserIDandMovieIDcolumns into sequences
We can then create a DataLoader using pytorch library to load the data in batches.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from torch.utils.data import DataLoader
train_loader = DataLoader(
train_data,
batch_size=batch_size,
num_workers=num_workers,
shuffle=True,
)
val_loader = DataLoader(
val_data,
batch_size=batch_size,
num_workers=num_workers,
shuffle=False,
)
Model
The model architecture is designed as in the original paper. Here are some of the specifications of the model:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
len(train_data) 162541
len(val_data) 162541
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
-----------------------------------------------------------
0 | item_embeddings | Embedding | 7.6 M
1 | input_pos_embedding | Embedding | 65.5 K
2 | encoder | TransformerEncoder | 3.6 M
3 | linear_out | Linear | 7.6 M
4 | do | Dropout | 0
-----------------------------------------------------------
18.8 M Trainable params
0 Non-trainable params
18.8 M Total params
75.197 Total estimated model params size (MB)
Training
To train a model we prepare a config.yaml file with all the necessary configurations including dataset, model architecture, hyperparameters and more.
The config file below trains a 4-layers BERT4Rec model on the MovieLens 100K dataset for 10 epochs. The framework allows sending metrics and training log to weights & biases. If you prefer to use tensorboard make sure to comment log_wandb out.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# log config
log_wandb: true
# Hyperparameter config
n_layers: 4
n_heads: 4
# dataset config
data_path: ./training_data/
# Attention: The following fields change from dataset to dataset
dataset: ml-100k
field_separator: "\t"
USER_ID_FIELD: user_id
ITEM_ID_FIELD: item_id
RATING_FIELD: ~
TIME_FIELD: timestamp
show_progress: true
load_col:
inter: [user_id, item_id, timestamp]
user: [user_id]
item: [item_id]
# model config
epochs: 10
train_batch_size: 3500
eval_batch_size: 3500
learning_rate: 0.01
user_inter_num_interval: "[0,inf)"
item_inter_num_interval: "[0,inf)"
filter_inter_by_user_or_item: false
neg_sampling:
uniform: 1
eval_args:
split: {'RS': [4, 1, 1]}
group_by: None
order: TO
mode: uni50
metrics: ['Recall', 'MRR', 'NDCG', 'Hit', 'Precision', 'MAP']
topk: 12
valid_metric: MAP@12
Evaluation
Recbole provides a variety of metrics to evaluate the performance of the model. The metrics are defined in the config.yaml file provided earlier. The metrics are calculated for each epoch and the best model is saved based on the valid_metric defined in the config file.
After many different experiments we can join all the metrics collected to evaluate the best configurations using weights & biases dashboard.
 Weights & biases dashboard results
Weights & biases dashboard results
Using wandb dashboard we can quickly and easily compare the results of different models and configurations in a human-readable format. We can also compare the results of different models on different datasets.
Using the model in inference
The model can be used in inference by loading the saved model and passing the user and item ids to the model. The model will return the predicted rating for the user and item.
The following steps are generally followed to use the model in inference:
- Load the saved model and the dataset (this is usually done in one step with recbole)
- Read the user’s history depending on the dataset used (movies, books, purchases, etc.)
- Convert the user’s history into a sequence of item ids (Create a lookup table for the item ids)
- Pass the user item ids to the model
- Get the predicted next items
- Convert the predicted item ids to the original items (using the reverse lookup table)
Conclusion
In this article we have seen how to use the recbole framework to train a BERT4Rec model. We have also seen how to use the weights & biases dashboard to compare the results of different models and configurations. The recbole framework is a great tool for training and evaluating recommender systems models. It provides a lot of flexibility and allows for easy experimentation with different models and configurations.
In general, BERT4Rec can only be used for sequential recommendation. It is not suitable for cold-start problems. It is also not suitable for recommendation problems where the user’s history is not available. For example, in the case of new items addition to the catalog, the model needs to be retrained to include the new items, which can be computationally expensive.
Furthermore, other state-of-the-art models such as GRU4Rec outperform BERT4Rec in terms of overall performance and training time.
Evaluation of many different recommender systems models using recbole on the ml-100k dataset:
| index | model | type | duration | best_valid_score | valid_score | recall | MRR | nDCG | hit | precision | map |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Pop | general | 1.48 | 0.4703 | True | 0.6663 | 0.572 | 0.5227 | 0.8842 | 0.1457 | 0.408 |
| 1 | ItemKNN | general | 5.45 | 0.2129 | True | 0.5762 | 0.291 | 0.3158 | 0.8231 | 0.1041 | 0.1909 |
| 2 | BPR | general | 3.4 | 0.2646 | True | 0.412 | 0.3542 | 0.3075 | 0.6366 | 0.0877 | 0.2238 |
| 3 | NeuMF | general | 4.07 | 0.4333 | True | 0.6573 | 0.5276 | 0.4928 | 0.8849 | 0.1402 | 0.3733 |
| 4 | RecVAE | general | 85.48 | 0.4678 | True | 0.6706 | 0.5688 | 0.5209 | 0.8922 | 0.1453 | 0.4039 |
| 5 | LightGCN | general | 118.88 | 0.3259 | True | 0.4859 | 0.4039 | 0.3694 | 0.6709 | 0.1041 | 0.2809 |
| 6 | FFM | context-aware | 5.25 | 0.1766 | True | 0.5615 | 0.2507 | 0.2908 | 0.8036 | 0.0988 | 0.1673 |
| 7 | DeepFM | context-aware | 5.2 | 0.1772 | True | 0.5625 | 0.2496 | 0.2907 | 0.8046 | 0.0991 | 0.1669 |
| 8 | BERT4Rec(2 layers) | sequential | 22.06 | 0.4363 | True | 0.6969 | 0.5409 | 0.5157 | 0.9018 | 0.1427 | 0.3929 |
| 9 | BERT4Rec(4 layers) | sequential | 29.42 | 0.4631 | True | 0.7461 | 0.7952 | 0.5884 | 0.9515 | 0.5502 | 0.4631 |
| 10 | GRU4Rec | sequential | 5.86 | 0.5854 | True | 0.7086 | 0.6778 | 0.6037 | 0.9038 | 0.1591 | 0.4989 |
| 11 | SHAN | sequential | 10.22 | 0.5201 | True | 0.5624 | 0.4984 | 0.4706 | 0.6555 | 0.1076 | 0.4025 |
Nevertheless, BERT4Rec one of the first approaches to utilize the Transformer architecture for sequential recommendation. It is a great starting point for anyone who wants to learn more about the Transformer architecture and how it can be used for sequential recommendation.