
TL;DR
The potential applications of chatbots are vast and varied. In this work, a chatbot is designed to automate customer service of an e-book store. This paper reviews the latest state-of-the-art frameworks for building chatbots and proposes a chatbot using Rasa and spaCy. The next step is setting up an evaluation framework for the concept. The results of the evaluation show that combining Rasa and SpaCy provides a high performance, high accuracy model that can be used in production scenarios.
 Demo of the final product in action
Demo of the final product in action
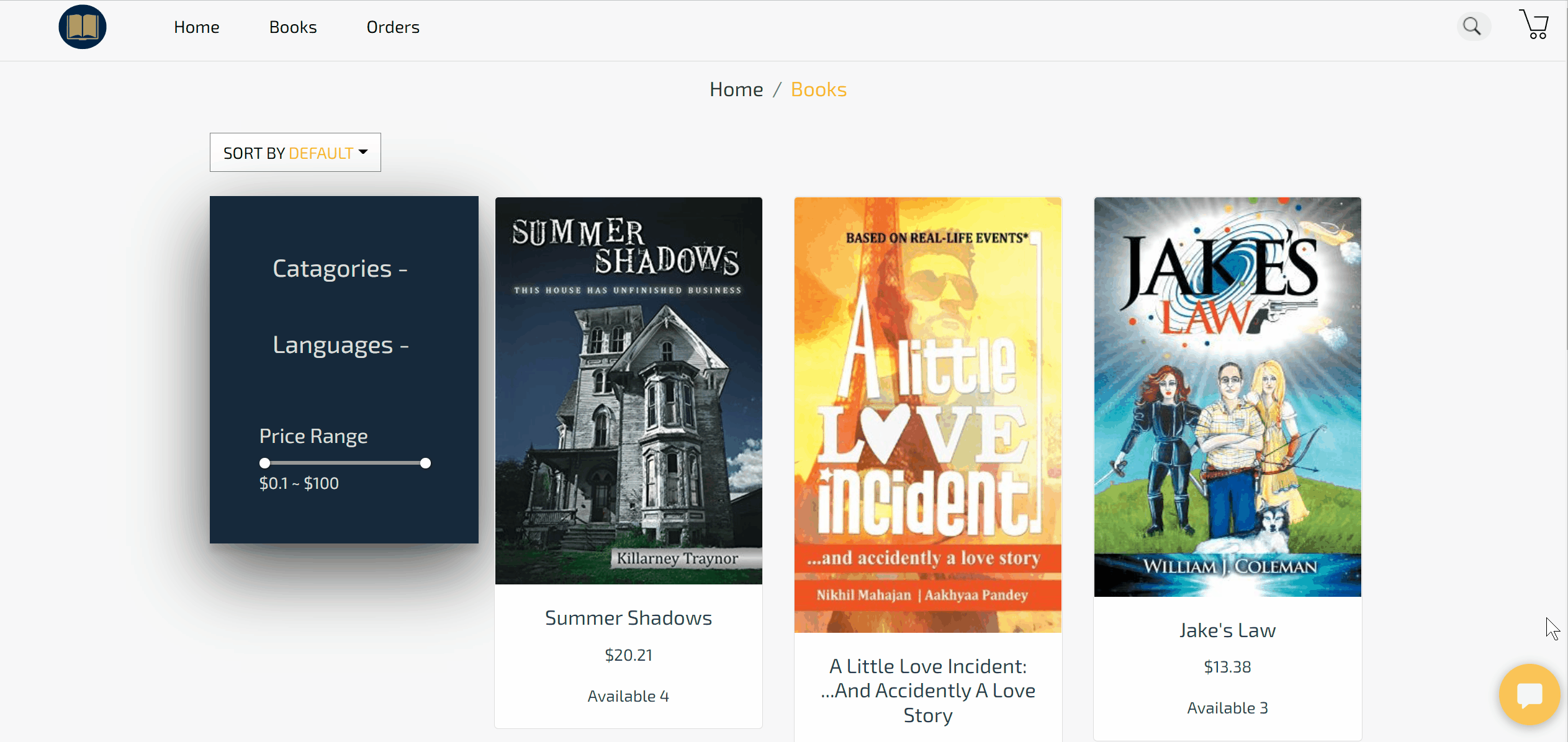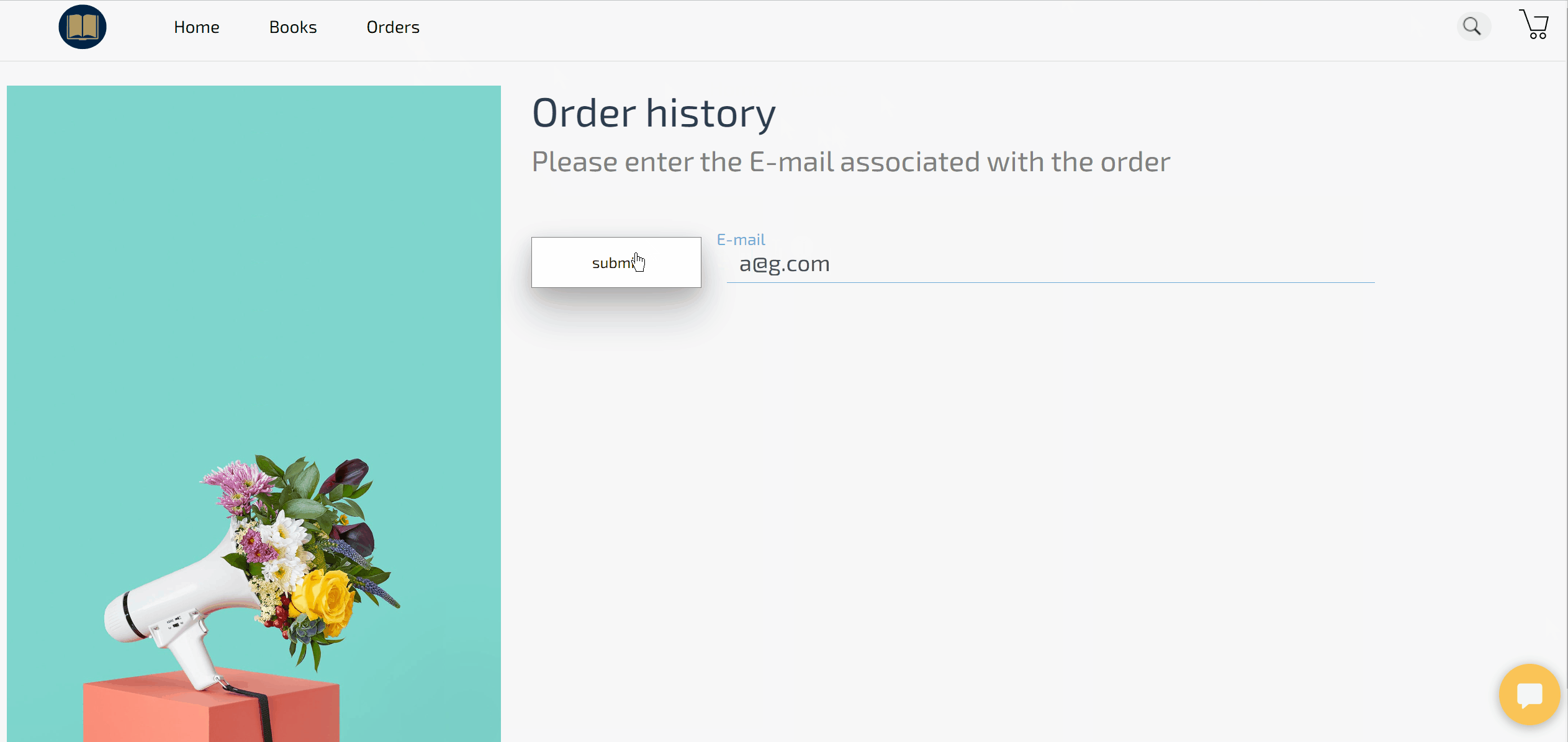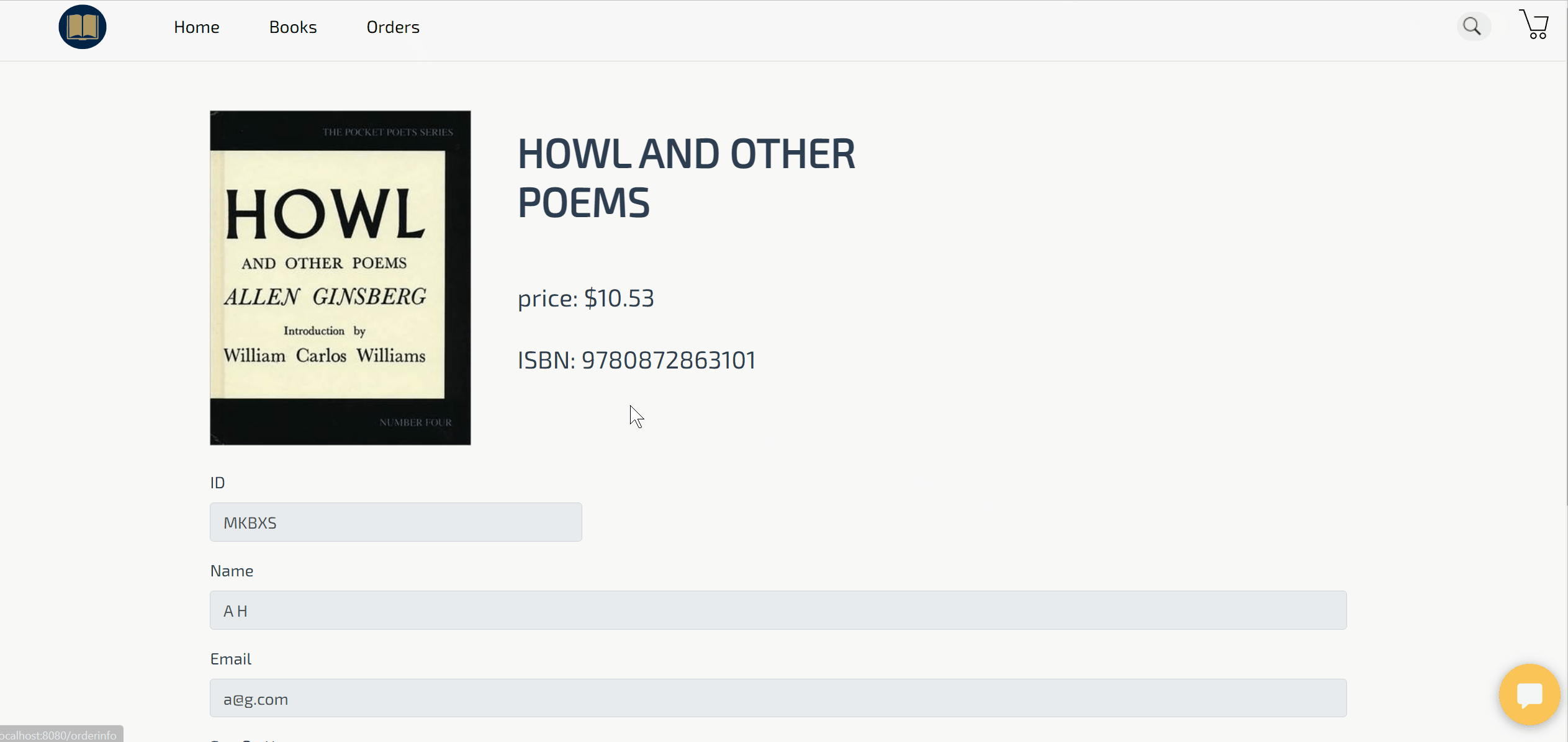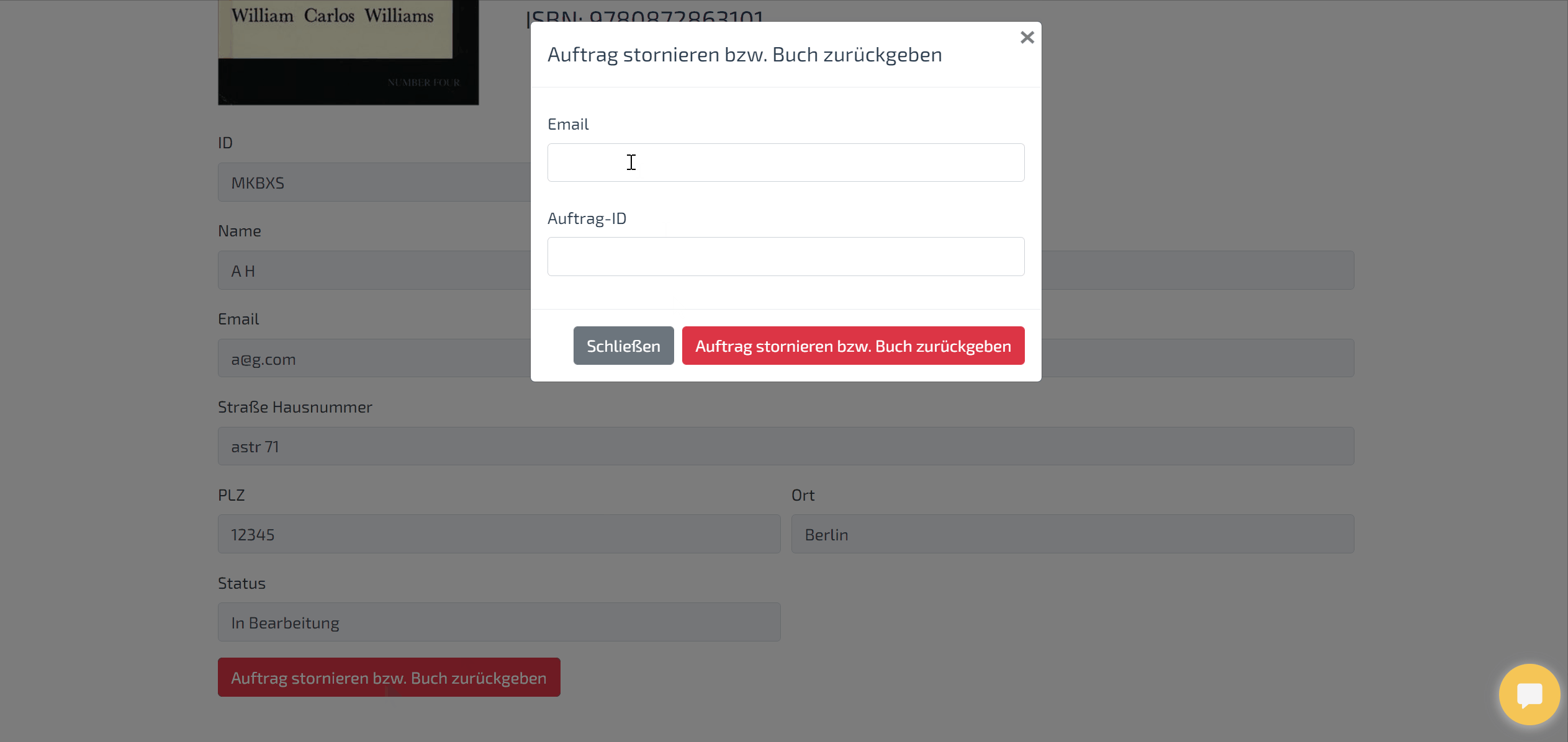 Demo of checking the order history after an order has been placed through the chatbot
Demo of checking the order history after an order has been placed through the chatbot
Introduction
Chatbots are computer programs designed to simulate conversation with human users. They use natural language processing and sentiment analysis to communicate in human language. Chatbots are more friendly and attractive to users than the static content search in FAQs lists (Costa, 2018). Chatbots offer users comfortable and efficient assistance when communicating with them by providing more engaging answers and directly responding to their problems.
Chatbots have been used for increasingly complex tasks, including notifications and simple conversations. In the last decade, chatbots have been used primarily for notifications, where no interaction occurs between the user and the bot, with the bot simply displaying messages and announcements. In the next stage of the assistant, the chatbot can interact with the user in various ways and have a simple conversation (RASA, n.d.).
In this work, a chatbot is implemented to automate an e-book store in order to provide customers with a more convenient and efficient shopping experience. The chatbot was implemented in Rasa, an open source framework which is supported by a large community. For Natural Language Processing, the spaCy library was used, which assists in syntactic analysis and the understanding of human language. The underlying web application of the e-bookstore is based on the Vue.js 2.0 web framework, using Node.js and MongoDB as backend technology. The application is implemented in the form of a set of microservices running in Docker containers and has an API implemented with Swagger.
The chatbot consists of the following components:
- Rasa Core: The main component of the Rasa stack. It takes care of all the messaging and dialogue management.
- Rasa NLU: This component assists the chatbot to understand natural language. The spaCy library supports with syntactic analysis and understanding of human language.
- Rasa NLG: This component helps the chatbot generate natural language responses.
The chatbot is integrated into the e-bookstore as a widget and is connected to the e-store’s API in the backend in order to answer customers’ queries.
The chatbot is evaluated on two aspects: technical and non-technical. In order to evaluate the NLU, technical metrics such as accuracy, precision, and confusion matrix are used. Moreover, the chatbot as a whole is assessed in terms of usability, including effectiveness and satisfaction.
Background
In this section, we list the technologies reviewed and used in this work.
Chatbot Frameworks
Chatbot frameworks are tools that allow developers to create chatbots more easily. They provide templates and libraries that make it simpler to design and program chatbots, and they may also include built-in natural language processing capabilities. Some popular chatbot frameworks include Dialogflow, Rasa, and Pandorabots.
| Chatbot Framework | Pro | Contra |
|---|---|---|
| DialogFlow |
|
|
| Rasa |
|
|
| Botpress |
|
|
Rasa is an open-source chatbot development platform for designing and building chatbots from scratch, or import existing chatbot models using the Rasa NLU and Rasa Core libraries. Rasa also offers machine learning for automatic chatbot training, and provides integrations with popular chatbot platforms.
Natural Language Understanding (NLU)
NLU is the process of understanding natural language text. It can be used to process questions and answers, or to extract information from unstructured text. There are different approaches to natural language understanding, including rule-based systems, machine learning, and artificial intelligence. NLU is used in a number of applications, including chatbots, voice recognition, and natural language processing.
There are various NLU Frameworks such as spaCy, Stanford CoreNLP, and OpenNLP. These frameworks provide a library of algorithms for natural language processing tasks such as tokenization, part-of-speech tagging, named entity recognition, and dependency parsing. Each framework has its own strengths and weaknesses.
Natural Language Processing (NLP)
NLP is a branch of AI that deals with the interaction between computers and human languages. It is used to process and analyze large amounts of natural language data. NLP is used in a variety of applications, including chatbots, voice recognition, and natural language understanding.
To build the NLP pipeline for the chatbot, we used the spaCy library. This is a free, open-source library for advanced natural language processing in Python. It is designed specifically for production use and helps to build applications that process and “understand” large volumes of text.
SpaCy is a newer framework, and it has gained popularity because of its ease of use and simplicity. In comparison with Stanford CoreNLP, it has several advantages, including faster and more memory-efficient operation and better documentation. Unlike CoreNLP, spaCy also includes a machine learning-based part-of-speech tagger. Moreover, spaCy integrates very well with chatbot frameworks such as Rasa and provides satisfactory results.
Natural Language Generation NLG
(Kale & Rastogi, 2020) proposes two methods for zero-shot and few-shot NLG. In the first method, schema-guided NLG, slots are represented by their descriptions in natural language. As for the second method, Template Guided Text Generation (T2G2), it uses simple templates to represent the actions of the system, then formulates NLG as an utterance rewriting task.
A study by (Santhanam & Shaikh, 2019) notes that approaches for designing dialogue systems use language model architectures or sequence-to-sequence models primarily.
The disadvantage of building conversational agents based on vanilla seq2seq is that the responses they generate are dull and generic (Santhanam & Shaikh, 2019). This is because the model is not able to learn the nuances of human conversation. In general, there isn’t much research into NLG compared to other AI subfields. The research on NLG is still in its early stages of development, and as such, there is also relatively little research on its effectiveness. However, there are a few key papers that provide an overview of the field and its challenges.
System Design
In this section, we will discuss the design of the e-bookstore and the chatbot as a combination of microservices.
The e-bookstore is implemented as a set of microservices running in Docker containers. The microservices are connected to each other via a REST API. The API is implemented with Swagger, which is an open source framework for designing, building, and documenting RESTful APIs. The chatbot is implemented as an independent microservice that is connected to the e-bookstore’s API in the backend. The chatbot is integrated into the e-bookstore as a widget and is connected to the e-store’s API in the backend in order to answer customers’ queries. The user communicates with the chatbot via a chatbot widget on the e-bookstore’s website.
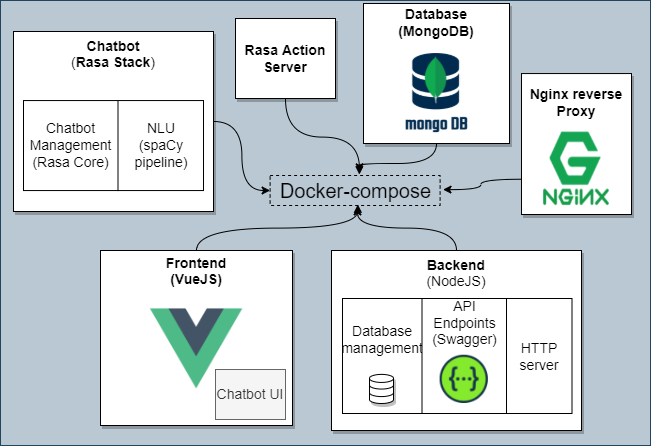 Sofware architecture as a dockerized microservice architecture
Sofware architecture as a dockerized microservice architecture
E-bookstore Service
There are several different web stacks that can be used when building an e-commerce store. One popular one is the LAMP stack, which stands for Linux, Apache, MySQL, and PHP. It gained popularity because it is open source. Another web stack worth mentioning is the MEVN stack, which stands for MongoDB, Express.js, Vue.js, and Node.js. This stack is popular because of its modularity and since it allows for more flexibility when building an e-commerce store. MEVN allows developers to build faster and more efficient applications.
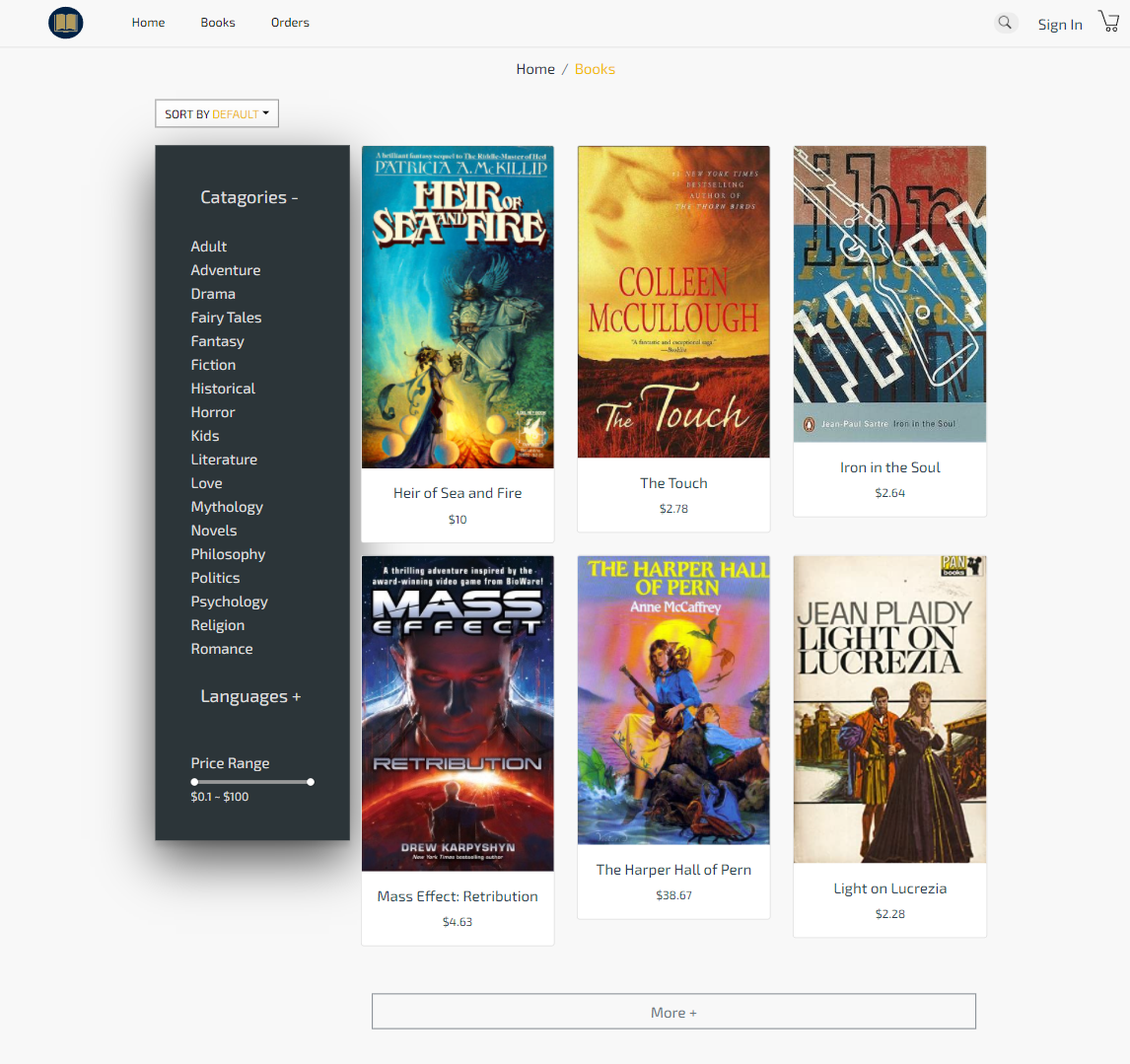 Demo of the bookstore front-end
Demo of the bookstore front-end
API documentation
Swagger.io is a platform for API documentation and development that enables developers to create, visualize, and share APIs via the Swagger hub. Swagger.io also allows generating code samples in multiple programming languages, making it easy to get started with the API development. Using the Swagger editor, users can design and test their API live. APIs are written in a YAML file format standardized by OpenAPI and Swagger foundation. The low-code nature of Swagger makes it easier for developers to develop, understand, and consume APIs.
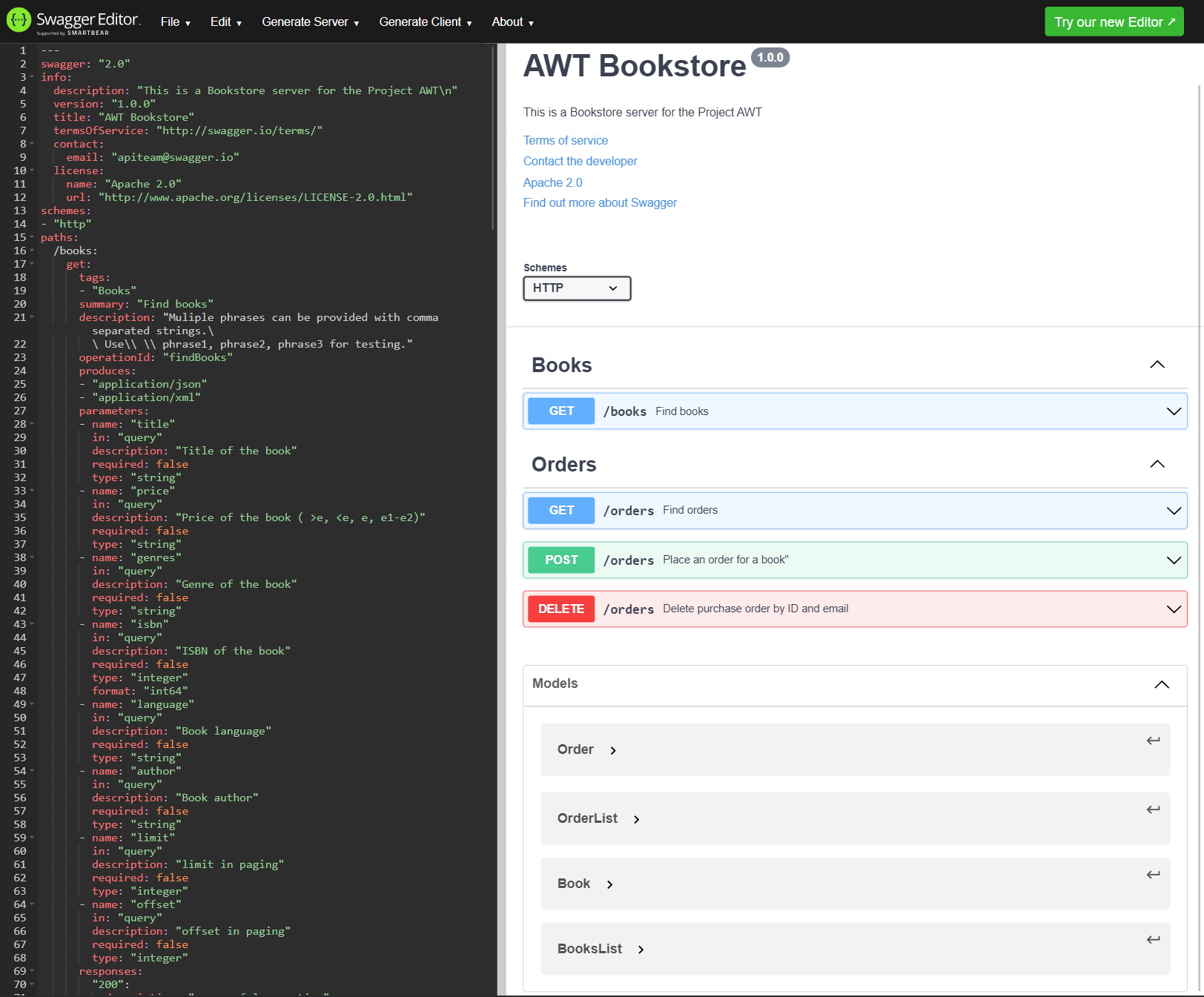 Designing the API with Swagger Editor
Designing the API with Swagger Editor
After designing the API, the Swagger editor can be used to generate both the server and client code. The generated code can be used to implement the API in any programming language. The generated code can also be used to test the API.
Designing chatbot stories
Designing chatbot stories can be done with a variety of tools. The most popular ones are DialogueFlow, Botsociety, and RasaX.
Botsociety is a tool that allows creating, sharing, and collaborating on chatbot stories. It has a built-in chatbot engine and conversations can be created by using drag-and-drop diagrams. There is the possibility to add in images, videos, and sound clips. The stories can then be exported to different chatbot frameworks such as Rasa and DialogueFlow.
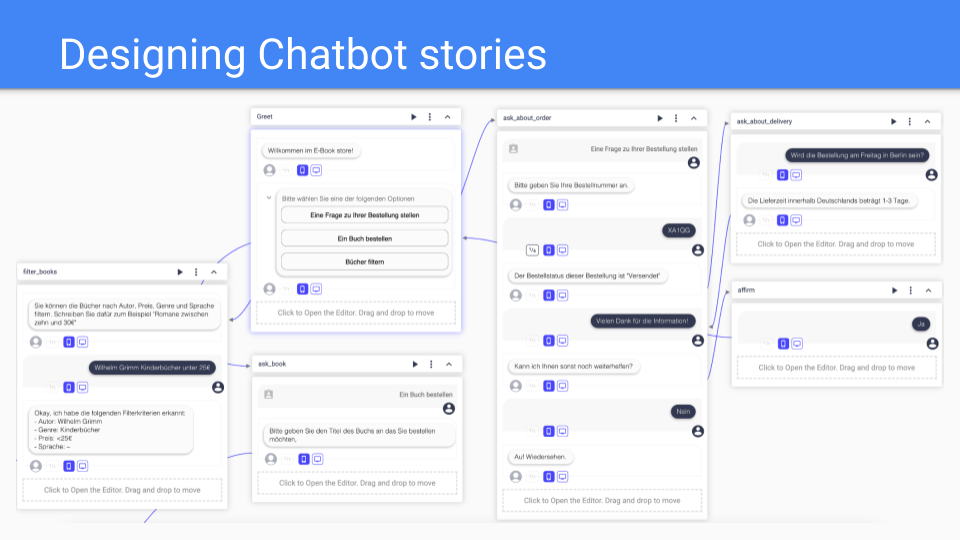 Designing chatbot stories with Botsociety
Designing chatbot stories with Botsociety
Individual components of the interaction with the user are logically combined in story blocks. Each of these blocks can contain multiple user inputs and chatbot messages and reactions.
As you can see here in the “greet” story block, botsociety supports not only chatbot output in the form of text, but also other formats such as buttons. For each user selection of buttons a separate storyline can be created. Loop backs between the individual blocks is also possible. This enables the design of complex interactions during which the user chooses to use not only one but several of the available functionalities of the chatbot.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- story: greet + ask about order + ask about delivery
steps:
- intent: greet
- action: utter_greet
- action: utter_offer_overview
- intent: ask_for_order_number
- action: utter_ask_for_order_number
- intent: give_order_number
- action: action_get_order_information
- action: utter_give_order_status
- intent: ask_about_delivery
- action: utter_info_about_delivery_time
- intent: mood_great
- action: utter_offer_further_assistance
- intent: deny
- action: utter_goodbye
Example of a generated story from Botsociety
Each of the stories consists of several steps, where a step is either an intent or an action. An intent on the part of the user is usually followed by one or more actions performed by the chatbot. An action in this case can be either a chatbot utterance or a custom function, also called custom action.
3asdasd4
Training the NLU
As there are not many German training datasets available and we wanted to train our model with entities like GENRE, WORK_OF_ART, and PRICE, we created and annotated our own training dataset. The dataset consists partly of e-bookstore specific queries, in particular to include training examples for the entities PRICE, GPE, and DATE, and partly of book reviews published by a German news site DER SPIEGEL book reviews, for the entities WORK_OF_ART, PERSON, and GENRE. To label the entities within the examples we utilized the annotation tool prodigy prodigy documentation.
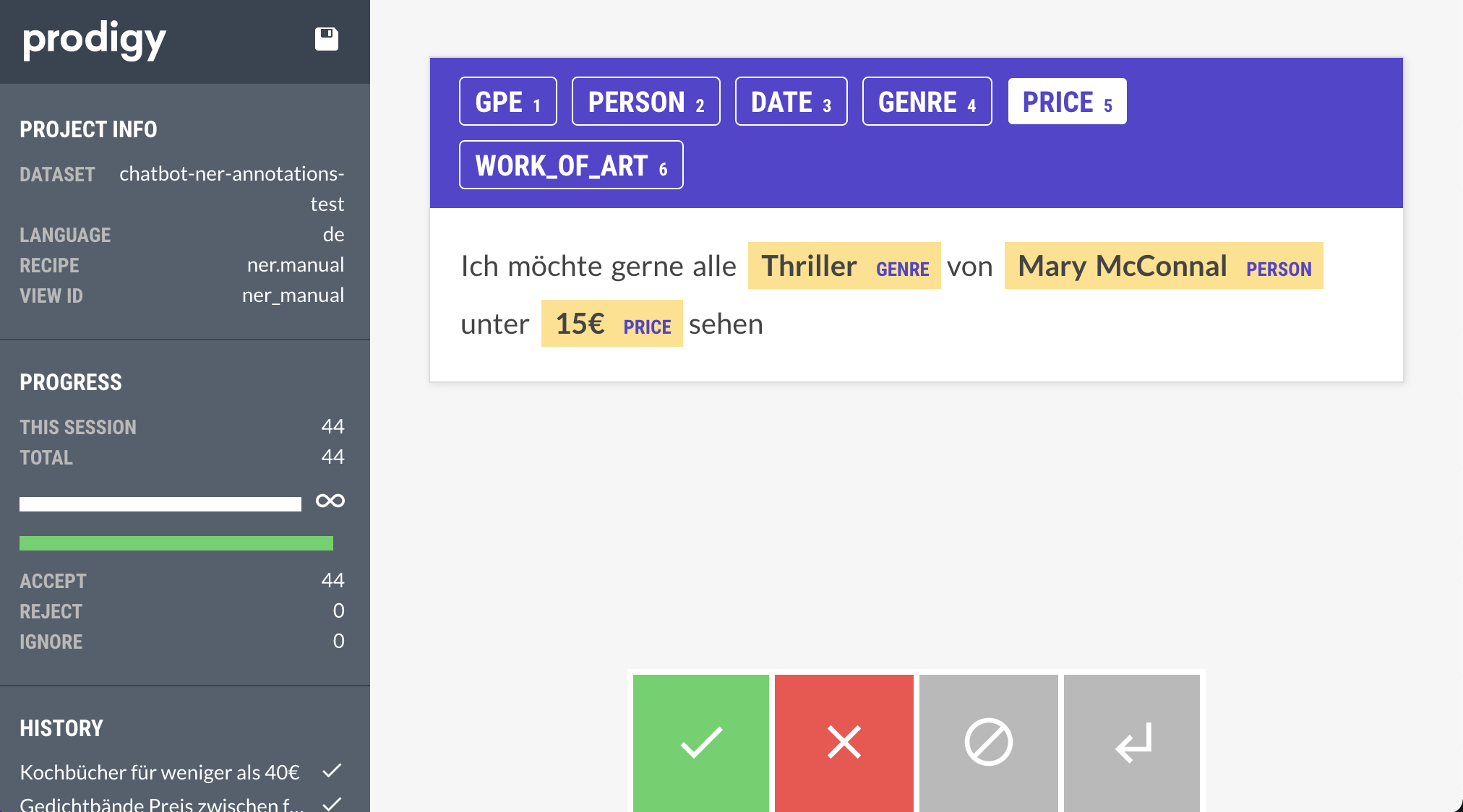 Example of a training example annotated with Prodigy
Example of a training example annotated with Prodigy
This tool has not only an appealing and easy to use user interface, but also offers the possibility to integrate a base model, in our case the spaCy model de_core_news_md, into the annotation process. In the first iteration we used the prodigy recipe ner.manual, where each entity has to be marked individually. In the second and third iteration, however, we were able to switch to “ner.correct” by leveraging our retrained base model, which was improved with the training data from the first iteration, so that the model can partially tag already learned entities, making the annotation process more efficient and faster. The annotated training data was converted to the .spacy format afterwards to train spaCy’s de_core_news_md model version 3.2.0 which was then integrated into the Rasa NLU pipeline as the NER component.
Evaluation
For the overall evaluation of the chatbot, we considered two main evaluative approaches. The first approach handles the technical evaluation, where many metrics from the built-in Rasa components as well as the adapted frameworks are reflected. The other approach sheds light on the non-technical aspects describing the usability, functionality, reliability, personalization, and interactivity.
The technical part of the evaluation confusion matrix involves precision, recall, and f1-score of the Rasa NLU Model, which contains intent classifiers. As mentioned in the NLU section the pipeline contains two custom components. The evaluation of those custom components had to be done separately. The technical metrics for the Rasa NLU model will be collected by using the following command:
1
Rasa test
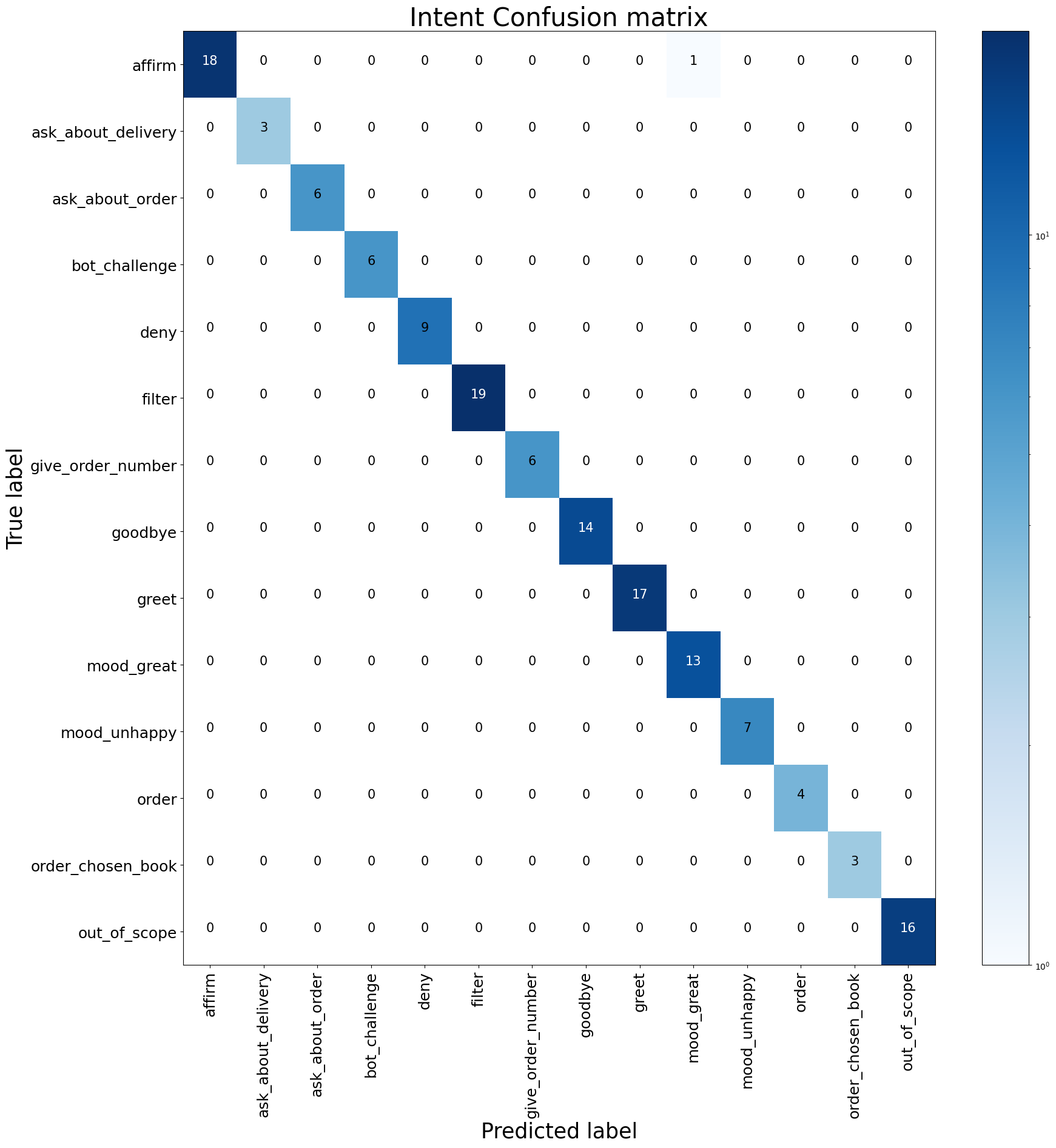 | 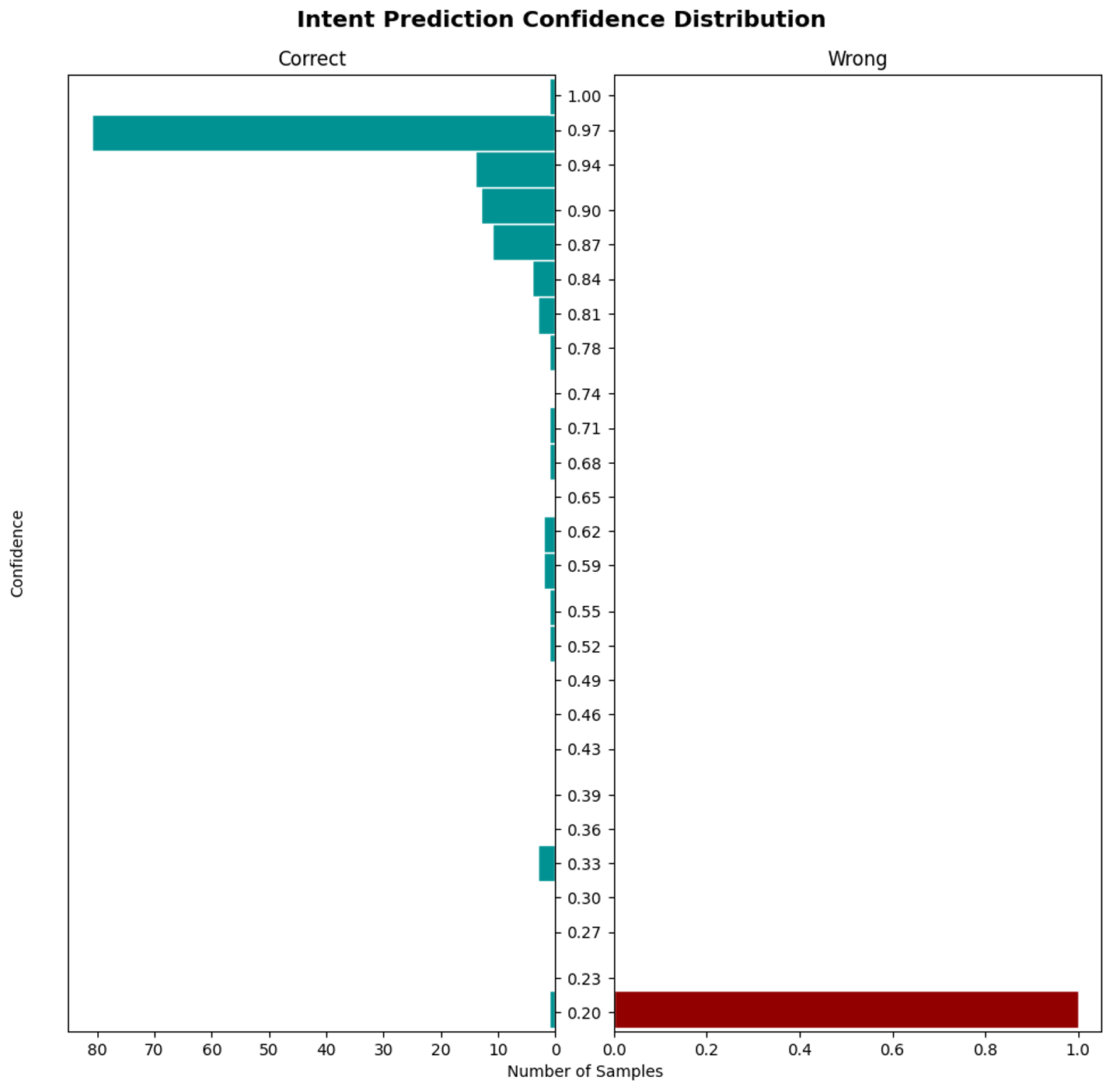 |
| Confusion matrix for the intent classification | Histogram of the intent classification |
The following table shows empirical results of the NLU shell. The NLP pipeline processes each input. Intent classification has been performed on the inputs, sentiments have been analyzed and expressed in a tuple of three emotions (positive, negative, neutral), and language has been detected with a strength score.
| User input | Detected intent | Sentiment | Language detection |
|---|---|---|---|
| Ich möchte gerne ein Buch bestellen. | order:0.723 | neg: 0.0 neu: 0.649 pos: 0.351 | de: 0.998 |
| Das ist genau was ich gesucht habe, vielen Dank =) | mood_great: 0.994 | neg: 0.0 neu: 0.597 pos: 0.403 | de: 0.993 |
| Bitte Bücher unter 15€ anzeigen. | filter: 0.999 | neg: 0.0 neu:1.0 pos:0.0 | de: 0.996 |
| Wird die Bestellung am Freitag in Mannheim ankommen? | ask_about_delivery: 0.857 | neg: 0.0 neu :1.0 pos: 0.0 | de: 0.890 |
| Spreche ich mit einem Menschen oder einen chatbot? | bot_challenge: 0.992 | neg: 0.0 neu: 1.0 pos: 0.0 | de: 0.999 |
| Wo gibt es das beste Essen in Berlin? | out_of_scope: 0.997 | neg: 0.0 neu: 0.693 pos: 0.307 | de: 0.957 |
| Das sind nicht die richtigen Filter… :’-( | affirm: 0.520 | neg: 0.528 neu: 0.472 pos: 0.0 | de: 0.998 |
E-bookstore overview
The e-book store offers users the option of renting books in a variety of languages, categories, and genres. Users can search for books by title, language, genre, or price, and rent them for a set period of time. They can also communicate with a chatbot for help with using the e-bookstore. The chatbot is able to understand the user’s input, answer questions the user may have about the e-bookstore, and help them rent books which are filtered based on their preferences. The chatbot can handle the following types of inquiries:
- Book information
- Book recommendations
- Order requests
- Order status
- Delivery times
The e-bookstore was implemented to accommodate the chatbot and provide the user with an interface to interact with the e-bookstore more naturally.
First, an open-source dataset containing more than 5,000 books is downloaded as a csv file. Each item in the csv file holds a variety of information, including title, ISBN, cover image, language, genres and other parameters.
Next, an API was designed using swagger-io as a script in YAML format. With Swagger, developers can easily design, test, and extend their APIs while reducing design errors. Once the API design is ready, users can generate the API server and API client in any framework they desire. The code of the generated node.js server is then extended to fit the e-bookstore’s requirements. To ensure data persistency, the backend server saves the books and orders in a MongoDB database instance. This ensures that even if the web application crashes, the data will still be available and easy to recover.
Additionally, a web application representing the user interface was designed using the JavaScript frontend framework Vue.js. The web application also uses HTML and CSS for styling. Both backend and frontend parts communicate via API calls according to the API documentation implemented earlier with swagger. The web application also contains a chatbot frontend widget, which is configured to connect to the Rasa chatbot server. Additionally, an nginx reverse proxy serves as a middleware between frontend and backend communications to avoid Cross-origin resource sharing (cors) issues.
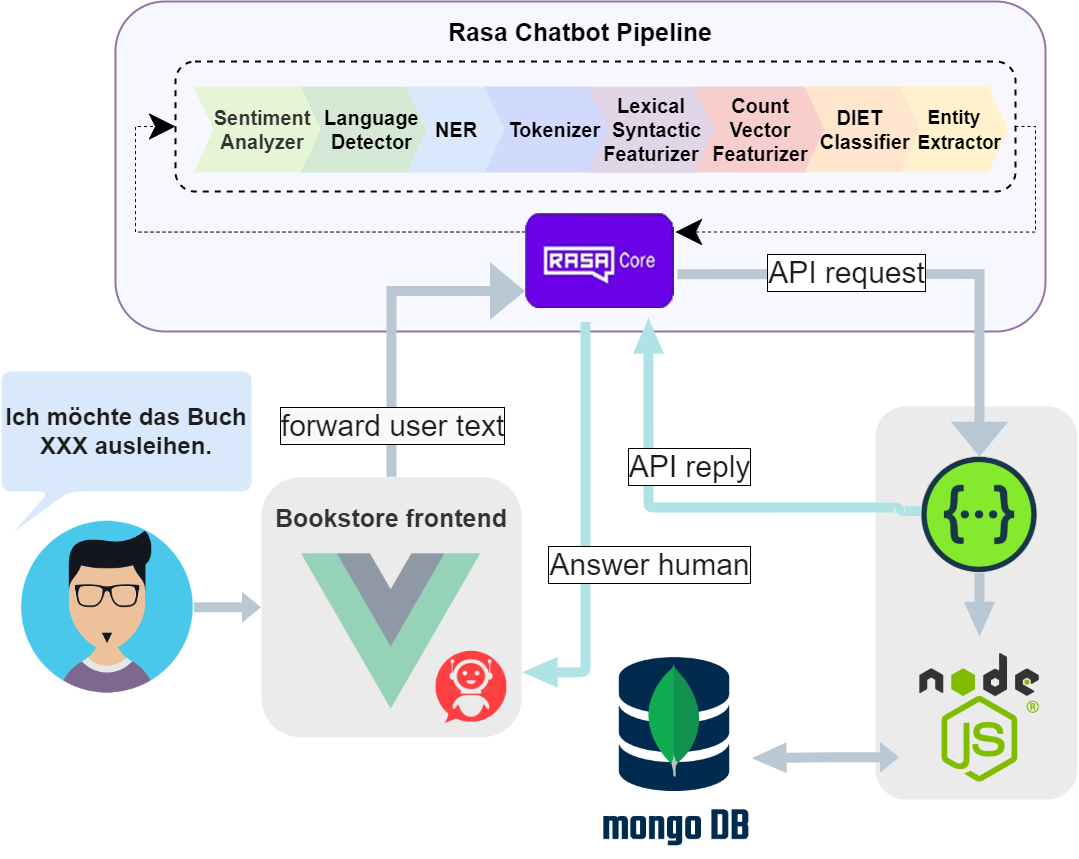 Data flow diagram of the bookstore
Data flow diagram of the bookstore
Conclusion
In this article, a practical integration of a chatbot service into an e-book store was presented. The solution provides users with a more interactive way of using the e-store. The chatbot service was utilized to provide users with information about each book, such as the summary, reviews, and ratings. In addition, functionalities were integrated into the chatbot framework to help users find the right book based on their preferences. Information about the status of an order and delivery times can also be requested by the user.
The concept of the e-bookstore supporting chatbot service aims at service-oriented and containerized architecture that runs on virtual hardware. The containerization of software using docker provides scalability and portability benefits to software development teams.
Using the open-source chatbot framework Rasa in combination with the spaCy NLP library resulted in a scalable chatbot solution that gives developers the freedom to extend their chatbots’ abilities. However, it proved difficult to take a proof-of-concept and turn it to a full-fledged product with Rasa.
The chatbot concept combines natural langauge understanding (NLU) solution designed with spaCy and Rasa, and a basic natural language generation (NLG) embedded in Rasa core framework.
In the NLU pipeline, several NLP components work together to extract different results from the user’s input. While some modules in the pipeline function independently, others are reliant upon the output of other modules. Several components were also custom designed to fit the chatbot’s scenario. The pipeline includes, for example, a language detection module based on the spaCy fastlang library. Another custom module using VADER analyzes the sentiments of user input. The results of the overall model, such as confidence score, sentiment tuple (negative, neutral, positive), and recognized language are extracted after every user message.
In the course of this work, a German-only chatbot was created. However, the integration of language detection has already laid the most important foundation for the extension of the German-language bot to a multilingual one. In this case, the already created German-language bot utterances could be translated into the detected language with the help of a translation model. Another possibility would be to create separate files for different languages instead of translating the existing texts. This would allow the use of country and language specific answers, such as information about delivery times.
References
- Costa, P. (2018). Conversing with personal digital assistants: On gender and artificial intelligence. Journal of Science and Technology of the Arts, 10(3), 59–72.
- RASA. Conversational AI: Your Guide to Five Levels of AI Assistants in Enterprise. https://rasa.com/blog/conversational-ai-your-guide-to-five-levels-of-ai-assistants-in-enterprise/
- Kale, M., & Rastogi, A. (2020). Template guided text generation for task-oriented dialogue. ArXiv Preprint ArXiv:2004.15006.
- Santhanam, S., & Shaikh, S. (2019). A survey of natural language generation techniques with a focus on dialogue systems-past, present and future directions. ArXiv Preprint ArXiv:1906.00500.